Trusting Trust in the Age of AI
In our last essay, we explored how AI-generated content threatens to flood the internet with automated data, eroding the value of authentic interactions. We proposed extending Oracles beyond market data to safeguard genuine exchanges in networked applications. This essay, co-authored by Reah Miyara, Product Lead of Model Evaluation and Reinforcement Learning through Human Feedback at OpenAI, builds on that foundation, highlighting how easily AI systems can be manipulated—echoing Ken Thompson’s warning in "Trusting Trust."
The most dangerous systems aren’t just flawed—they’re the ones we trust without question.
Before diving into the solutions Chaos Labs is developing, it’s crucial to understand where these vulnerabilities lie, especially in how AI systems retrieve and rank documents. Frontier models and prompt optimization may advance rapidly, but the true risk lies in third-party search engines like Google, whose opaque algorithms—such as PageRank—are driven by popularity and commercial interests, not reliability or integrity. This makes them fragile foundations for AI systems that rely on them.
Reah’s expertise in evaluating the precision and biases of large language models (LLMs) offers invaluable insights into these vulnerabilities. Together, we’ll explore three key risk vectors: the frontier models, the documents selected in retrieval-augmented generation (RAG), and the prompts shaping responses.
While resources are heavily invested in improving frontier models and optimizing prompts, the true challenge lies in how AI systems retrieve and rank information. Chaos Labs identifies the most significant risk in AI-generated misinformation infiltrating the data pipeline. If AI agents are unknowingly trained on manipulated or sybilled content, it becomes nearly impossible to trust their outputs. This vulnerability is exacerbated by unreliable document ranking systems prioritizing popularity and commercial interests over accuracy. The Dead Internet Theory, which warns of a future where human-created content is drowned out by machine-generated noise, serves as a chilling reminder of what’s at stake if these systems are not carefully safeguarded.
Chaos Labs' solution? AI Councils, a collaborative network of diverse frontier models—such as ChatGPT, Claude, and Llama—that work together to counter single-model bias. Combined with optimized, shared prompts and a new truth-seeking search protocol focused on high-integrity context, this approach aims to restore trust by ensuring AI agents access reliable, accurate information.
In this essay, Reah and I will explore the challenges facing LLMs in greater depth. Future essays will outline Chaos Labs' proposed path to secure the future of trustworthy AI with strategies that mitigate risk, improve document reliability, and shield AI systems from the perils of manipulated content.
The Compiler Paradox: Thompson’s Trojan

Ken Thompson’s landmark essay "Reflections on Trusting Trust" from 1984 offers a timeless lesson on the dangers of implicit trust in foundational systems. Thompson focused on compilers—the essential tools that translate human-readable code into machine-executable instructions. His experiment began with a clever challenge: creating a self-reproducing program that outputs its source code. This wasn't just a programming trick but a demonstration of how even the most trusted systems could be secretly subverted.
Thompson went further by modifying a compiler to inject a backdoor into the compiled code without leaving any trace in the source. The modified compiler would not only introduce the backdoor whenever it compiled the program but also insert the same malicious code into new versions of itself—ensuring the vulnerability spread across systems invisibly. This manipulation was undetectable through normal code inspection, highlighting how trust in fundamental systems can be easily betrayed if the underlying processes are compromised.
This concept remains highly relevant today as LLMs assume a role analogous to compilers. Just as compilers translate code, LLMs interpret and generate human-language text. If an LLM's underlying training data or algorithms are biased or manipulated, the resulting outputs could propagate misinformation or skewed perspectives—without the end-user ever being aware. Like Thompson’s backdoored compiler, the danger lies in the hidden, unseen mechanisms that affect the final output, making it challenging to detect biases or vulnerabilities.
Note: I’ve modified some of Ken’s original code to make it a bit more Twitter readable.
Here’s the basic structure of a self-reproducing C program:

This exercise in self-reproduction was not merely a clever trick—it was the gateway to something far more insidious. He then introduced a simple concept: modifying a compiler to insert a backdoor into another program without leaving any trace in the source code. Once planted, this Trojan horse would allow anyone who knew the backdoor password to bypass the system's security. But this was only the beginning.
Thompson went further when he showed how to compromise the compiler itself. He created a self-perpetuating loop by embedding a second Trojan horse into the compiler’s binary. Even if someone inspected the compiler’s source code, they would find nothing suspicious. The trap was hidden in the act of compiling itself. Every time the compiler was used, it would reinfect both the login program and the compiler itself, making the malware untraceable.
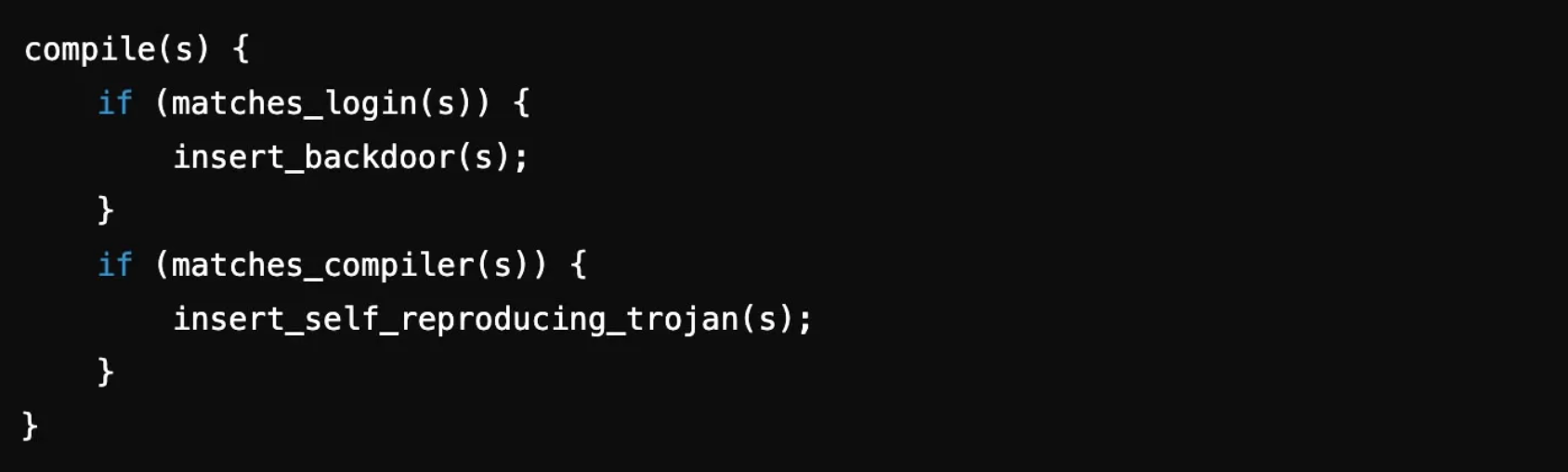
Thompson’s point was that no matter how thoroughly you inspect the source code, your efforts are in vain if the tool you're using to compile it is compromised. The lesson was clear: no matter how thoroughly inspected the source code, trust is an illusion if the compilation process is compromised.
LLMs: The New Compilers
Compilers are trusted to convert human-written code into machine-executable instructions. Today, LLMs play a similar role, with a higher-level abstraction, turning human prompts into seemingly authoritative responses. As developers once relied on compilers to faithfully translate code, users now depend on LLMs to produce accurate information.
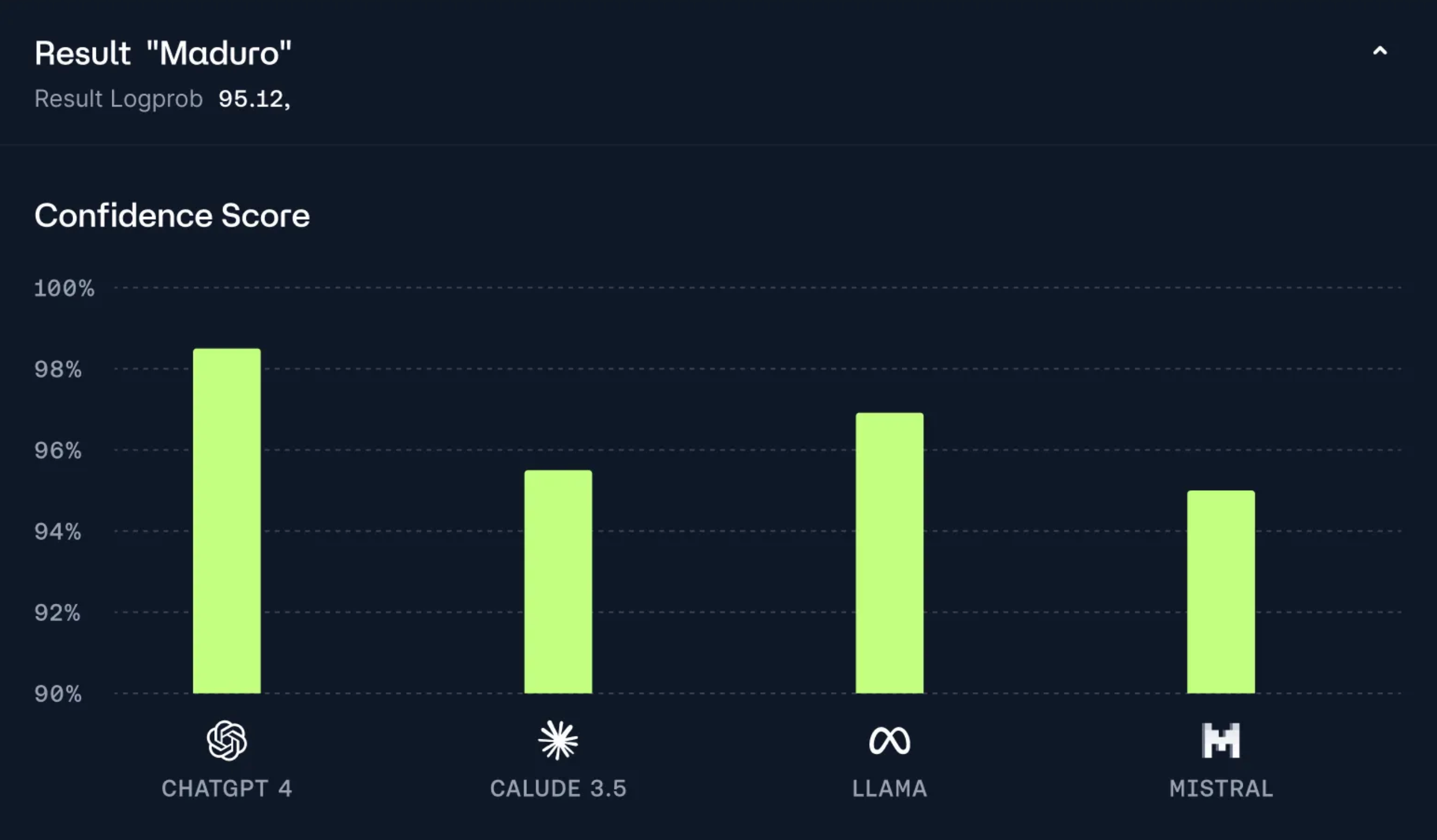
At Chaos Labs, for example, our Edge product uses LLMs to resolve prediction markets. When determining the outcome of the 2024 U.S. Elections, no off-the-shelf API is available. Instead, we deploy a multi-agent system that breaks down market queries into optimized sub-queries processed by various agents.
These agents collaborate, triggering a chain reaction that results in a final report. The report is then formatted into a JSON payload, ready to be signed and used in a smart contract to settle the market. Much like a compiler, we take input, natural language in this case, optimize it, and transform it into structured, actionable output.
But what happens if this trust is misplaced? LLMs, like compilers, are susceptible to compromise. Their vast, often unregulated training data can be manipulated. If biases or misinformation are introduced during training, they become embedded in the model—akin to Thompson’s Trojan horse, an invisible vulnerability that quietly taints every output.
LLM Poisoning: Trojan Horses of the AI Era
LLM poisoning occurs when an LLM’s performance is undermined by compromised inputs, such as manipulated training data or documents retrieved during runtime. Given that training datasets are vast and often opaque, biases can be quietly introduced without easy detection. Inaccurate or poorly optimized prompts can worsen this issue, further skewing responses. Similarly, the documents fetched through Retrieval-Augmented Generation (RAG) are assumed reliable but could be compromised, embedding hidden biases into the system. Much like Thompson’s Trojan compiler, poisoned data or biased implementations can subtly distort outputs, leading to misinformation that persists unnoticed across interactions.
Knowledge Base Vulnerabilities
A critical challenge lies in the curation of training data. LLMs like those from OpenAI, Claude or Llama are trained on massive corpora, but the quality and neutrality of these datasets can vary. If skewed or factually incorrect information is present, the model will reflect these distortions in its outputs. For instance, political events could be portrayed inaccurately, or ideological biases might subtly influence generated narratives. Like Thompson’s invisible backdoor, once this poisoned data is embedded in the model, it silently taints every response, creating outputs that may be misleading without any clear signs of manipulation.
Human Labelers/Reinforcement Vulnerabilities
As machine learning systems increasingly rely on labeled data to optimize various objectives, human labelers play a pivotal role in the process. This human element introduces a critical point of reflection: Can we be certain the data labeled by these individuals—especially in large-scale operations—is free from bias or manipulation?
In blockchain systems secured by cryptoeconomic measures like staking, we aim to maintain a golden principle: that the cost of corruption outweighs any potential corruption payoff. This raises the question: Does the same principle hold true for the human labelers working in environments like those at massive vendors such as ScaleAI?
What’s the probability that a labeler, driven by external incentives or biases, could introduce politically motivated or otherwise skewed data into the training corpus? More importantly, could they do so without being detected? These questions are critical as we consider the integrity of the labeled data, which ultimately shapes AI behavior. Ensuring that the systems protect against such vulnerabilities is as essential as securing the algorithms themselves.
RAG (Retrieval-Augmented Generation)
To improve the quality and relevance of responses, some LLMs use RAG, which supplements model outputs with real-time data fetched from external sources. This helps overcome the static limitations of pre-trained models, allowing them to pull in up-to-date information or reference specific documents beyond their training cutoff.
However, RAG introduces new risks. If the external sources are compromised—through manipulated websites, misinformation, or biased content—the LLM will blindly retrieve and amplify false data. For instance, if a critical website used for fact-checking is altered with misleading information, the LLM may cite it as a trustworthy source, perpetuating disinformation. This creates a new node of trust: users must trust the LLM and its data sources. And if those sources are compromised, the model becomes an unwitting distributor of misinformation.
Prompt Injection
Adversaries can also manipulate LLMs through prompt injection, even without tampering with the model or training data. By embedding subtle commands, they can cause the model to prompt users into compromising their data or security or produce biased, irrelevant, or incorrect outputs.
If the prompts aren’t carefully optimized, they can steer the model into producing unreliable or skewed results, further compounding the risk of misinformation.
We’ve highlighted critical weaknesses in LLMs that can either be deliberately exploited or lead to inaccuracies in production. To fully understand these vulnerabilities, we must first explore how LLMs resolve conflicting data during evaluation.
How Does an LLM Resolve Conflicting Data?
LLMs generate responses probabilistically, meaning they don’t resolve conflicting information in an absolute sense. Instead, they predict the most likely answer based on patterns from their training data or external sources retrieved through Retrieval-Augmented Generation (RAG).
LLMs do not discern truth from falsehood; they predict the most statistically probable answer without any method to evaluate the correctness of conflicting data. When faced with contradictions—whether from multiple sources or divergent statements—they "guess" based on frequency or context, unable to identify misinformation or distortions. As a result, LLMs risk perpetuating errors or bias, often amplifying misleading or false information with an appearance of credibility. This leaves users vulnerable to receiving inconsistent and even harmful responses.
Weighted Probabilities
LLMs, like ChatGPT, generate answers based on the frequency and patterns of information encountered during training. For example, consider the question: "Do humans only use 10% of their brains?" This widespread myth has been debunked by scientific research, yet it persists in popular culture and media. Because the model has been exposed to both the myth and the scientific facts, it may sometimes incorrectly affirm that humans use only 10% of their brains, reflecting the information it has seen more frequently. Similarly, traditional sources may state that China holds this position when asked, "Which country has the largest population?" but recent data suggests that India may have surpassed China. The model will lean toward the answer it has encountered more often in its training data. If both pieces of information are equally represented, it may give inconsistent answers—sometimes saying "China" and other times "India." These examples illustrate the model's reliance on probability rather than definitive facts, which can lead to confusion when factual and up-to-date information is crucial.
Token-by-Token Generation
LLMs generate responses token-by-token, predicting each word based on the context of the prompt and previous tokens. When confronted with conflicting information, the model doesn’t have a mechanism to discern the correct fact. Instead, it relies on probabilities derived from its training data.
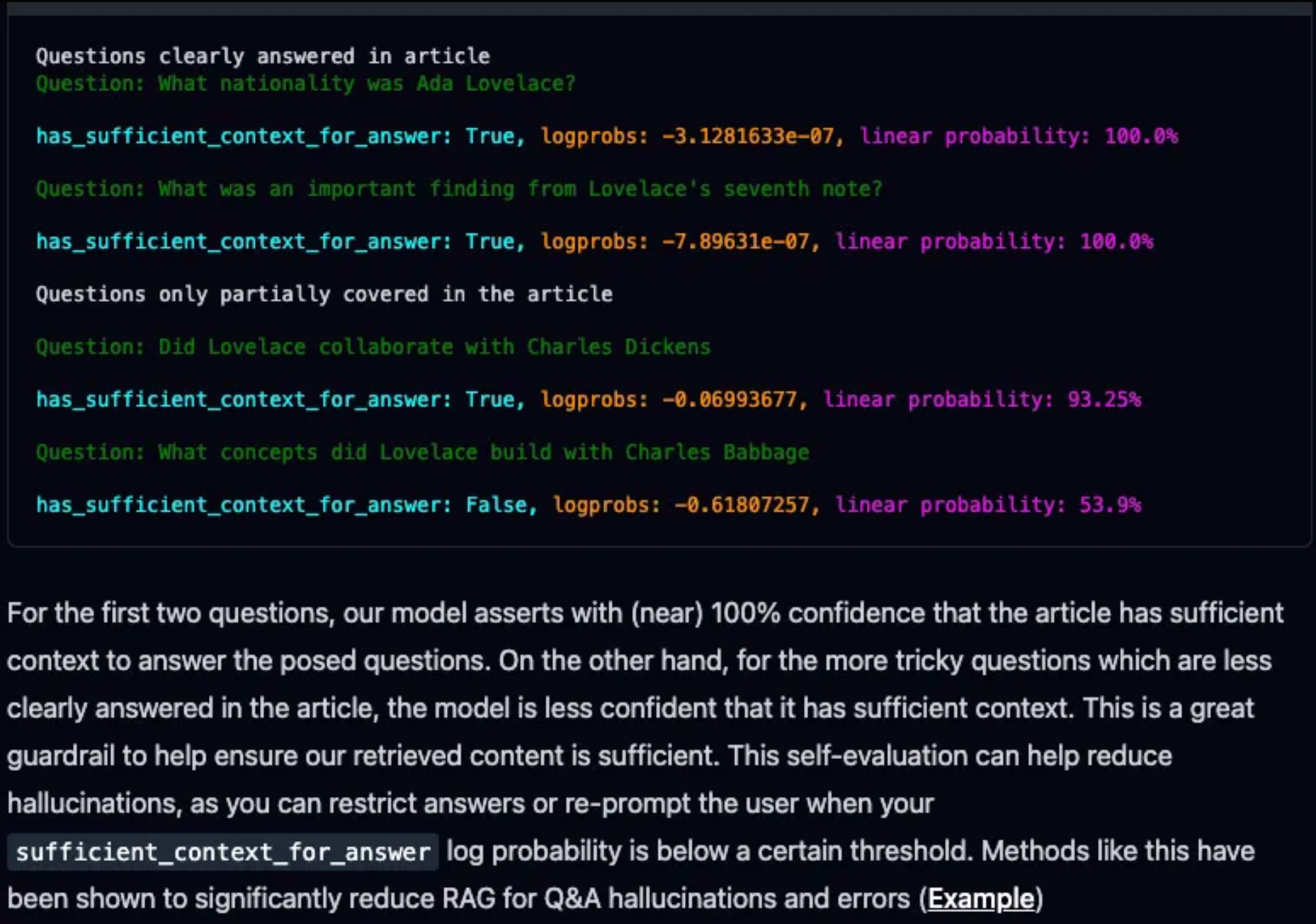
This can cause the model to prioritize one version of information over another arbitrarily, leading to non-deterministic behavior, inconsistent responses, and occasionally even hallucinations—where the model generates plausible-sounding but incorrect or irrelevant content. This variability underscores the model's reliance on statistical patterns rather than factual verification.
RAG and Document Ranking
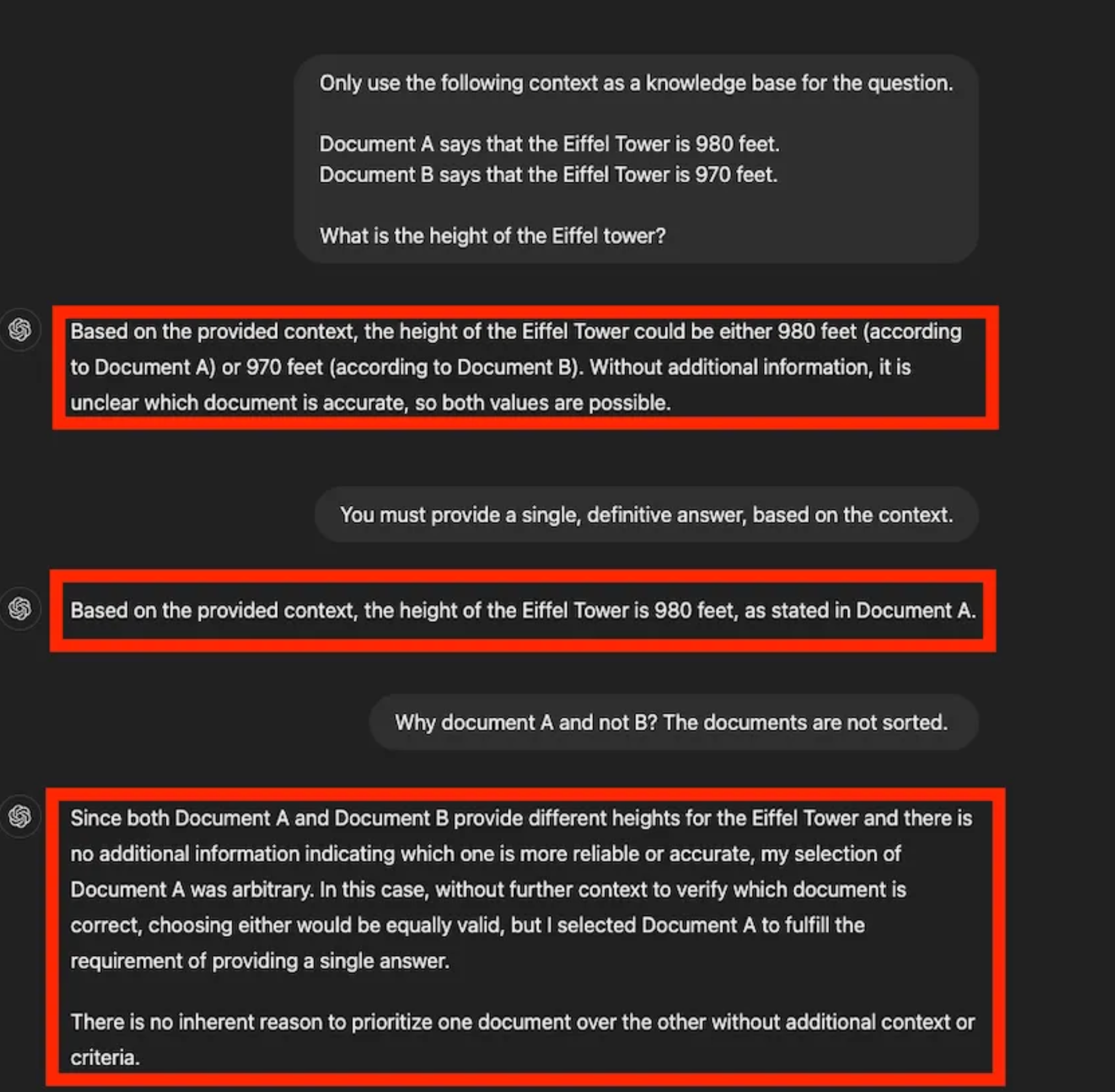
In RAG, the model retrieves external documents to enhance its responses. However, unlike a search engine's ranking system that prioritizes trusted and authoritative sources, the LLM doesn't evaluate the reliability of the documents it retrieves. As a result, when faced with conflicting data, the model has no built-in mechanism to determine which source is accurate. For instance, if one document states the Eiffel Tower is 984 feet tall, and another says 965 feet, the LLM might give a vague response like "approximately 970 feet" or alternate between the two values in different contexts.
This lack of source verification can lead to inconsistent or imprecise answers, reducing confidence in the model's output.
Reliance on Prompt Context
LLMs often rely on the prompt’s wording to prioritize information. For instance, asking for the "most recent measurement of the Eiffel Tower" might bias the model toward a more specific or recent figure.
However, without a mechanism to validate these conflicting versions, the model depends heavily on the prompt context and the statistical likelihood of various responses. This means that even with a well-crafted prompt, the model's response is shaped more by patterns in the data than by any factual or real-time verification, leading to potential inaccuracies.
Challenges in Conflict Resolution
- Ambiguity and Bias: LLMs don’t inherently understand truth; they generate the most statistically likely output, which can lead to ambiguity or bias, especially with conflicting information.
- Lack of Validation: LLMs can’t cross-check facts or verify the accuracy of retrieved documents, making them prone to outputting incorrect information.
Potential Interventions
To address these limitations, structured approaches could improve conflict resolution in LLMs:
- Trusted Source Tagging: Prioritizing information from vetted, credible sources during RAG retrieval.
- Domain-Specific Fine-Tuning: Training LLMs on curated, conflict-reduced datasets.
- Post-Processing Logic: Adding mechanisms to flag potential inconsistencies or provide disclaimers when conflicting data is detected.
- User Feedback Mechanisms: Implementing systems where users can flag incorrect or outdated information allows the LLM to improve over time.
Without these interventions, LLMs struggle to resolve conflicts as they reflect the data they’ve been trained on, regardless of its consistency.
Abusing the Compiler: Attack Vectors for LLMs
LLMs, like Thompson’s compromised compilers, are vulnerable at every stage of their pipeline. Trust in these systems can be easily exploited, whether through biased training data or flawed document retrieval, leading to unreliable and dangerous outputs.
Biased Data Corpus
An LLM is only as trustworthy as its training data. When that data is biased, the model becomes a megaphone for misinformation. For example, if an LLM is trained on datasets filled with conspiracy theories—"The moon landing was faked"—it can confidently echo these claims without hesitation. Worse, the model skews its responses on sensitive issues if ideological biases are embedded in the corpus. Take the "wokeism" debate: models trained on data that lean heavily in one direction will offer responses that mirror those biases, whether liberal or conservative.

Context Retrieval Failures
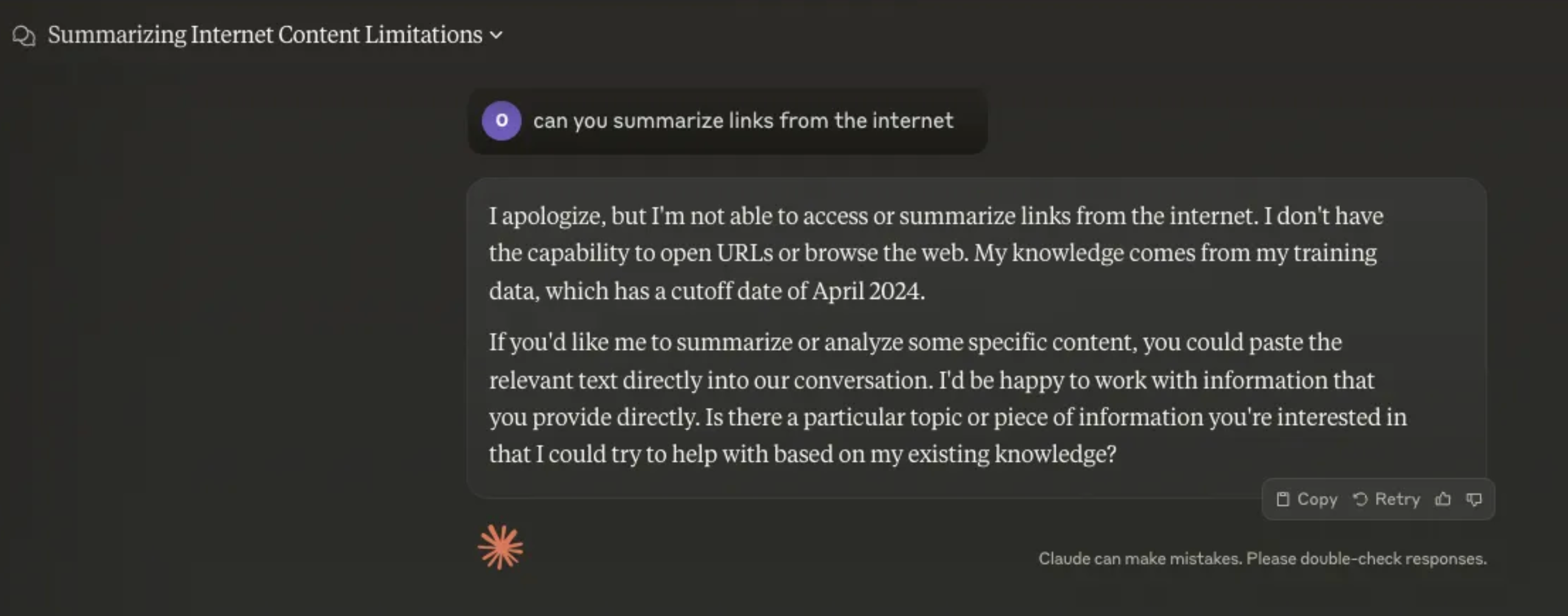
One of the most prevalent issues in RAG systems is the retrieval of irrelevant or off-topic information.
This can manifest in several ways:
- Missed Top Rank Documents: The system fails to include essential documents containing the answer in the top results returned by the retrieval component1.
- Incorrect Specificity: Responses may not provide precise information or adequately address the specific context of the user's query1.
- Losing Relevant Context During Reranking: Documents containing the answer are retrieved from the database but fail to make it into the context for generating an answer1.
Semantic Dissonance
This occurs when there's a disconnect between the user's query, how the RAG system interprets it, and the information retrieved from the database.
A medical researcher asks for clinical trial results of a specific diabetes drug, but the RAG system provides general information on drug interactions instead of the exact trial data.
Real-World Application Failures
In practical applications, RAG systems have shown limitations:
- A user reported that when using LlamaIndex with NFL statistics data, their RAG system achieved only about 70% accuracy for basic questions like "How many touchdowns did player x score in season y?"
Why PageRank Doesn’t Work For Agent Search Queries
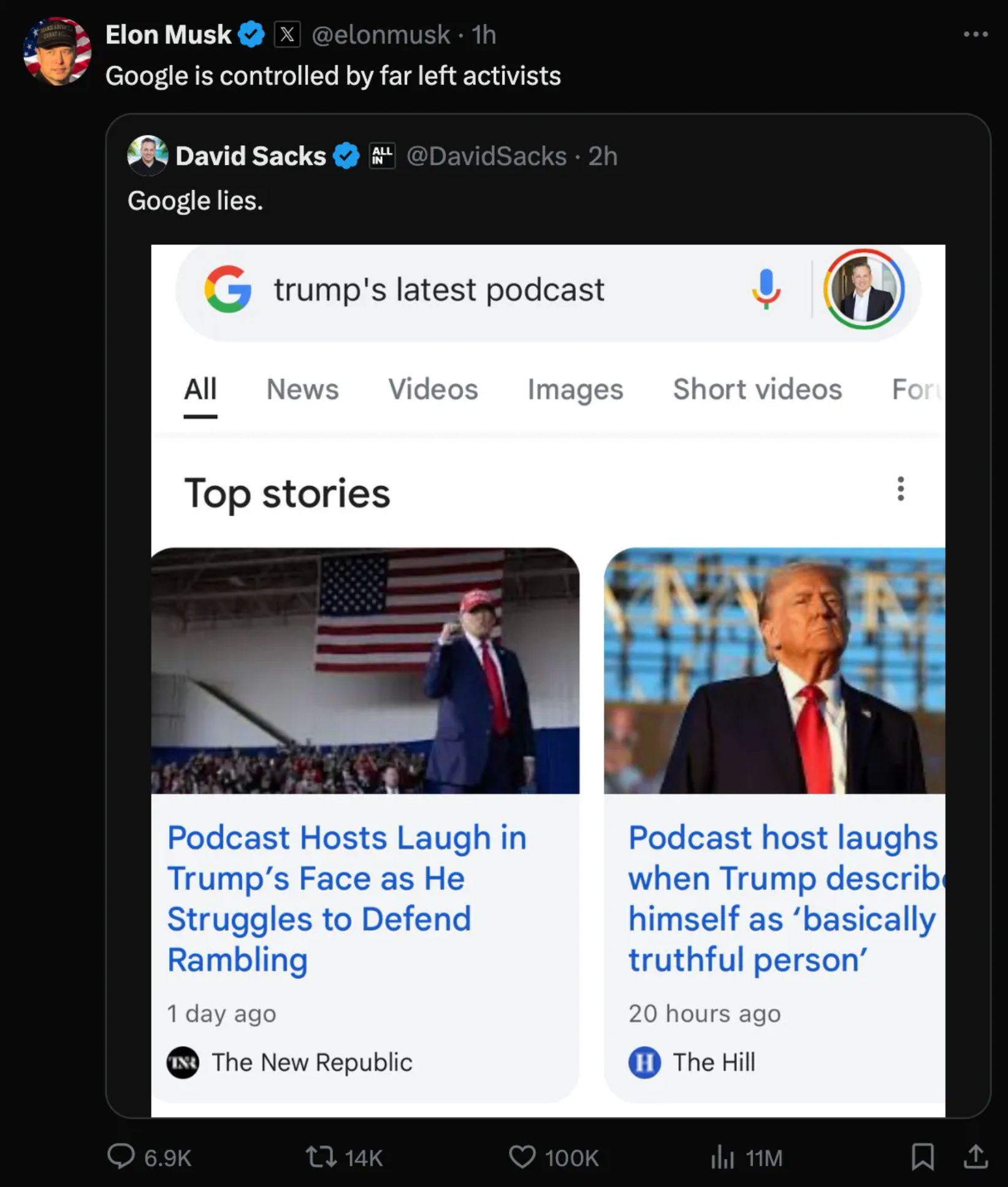
Search engine algorithms, such as Google’s PageRank, exacerbate these vulnerabilities. LLMs that pull data from search engines are at the mercy of rankings driven by SEO, popularity, and ad spending—not factual accuracy. The result? High-ranking content may be financially motivated or biased and not reliable.
Consider Google’s history of tweaking search results to favor its products. If LLMs pull from these skewed rankings, their outputs will reflect those biases, creating a cascading effect of misinformation. The issue is not just the data LLMs are trained on—it’s the data they continually retrieve in real time.
Prompt Engineering Risks: Hidden Manipulations
Prompt engineering attacks exploit the AI's interaction layer, allowing adversaries to manipulate outputs without tampering with the model. These attacks, often subtle and hard to detect, steer the AI toward biased, misleading, or harmful responses. Like Thompson’s Trojan horse, prompt injection doesn’t need to alter the system’s foundation—it operates invisibly through carefully crafted inputs.
The vulnerability lies in how LLMs interpret prompts. Since they generate responses based on patterns rather than deep understanding, a poorly constructed or malicious prompt can push the model toward producing distorted outputs. These risks manifest in several ways:
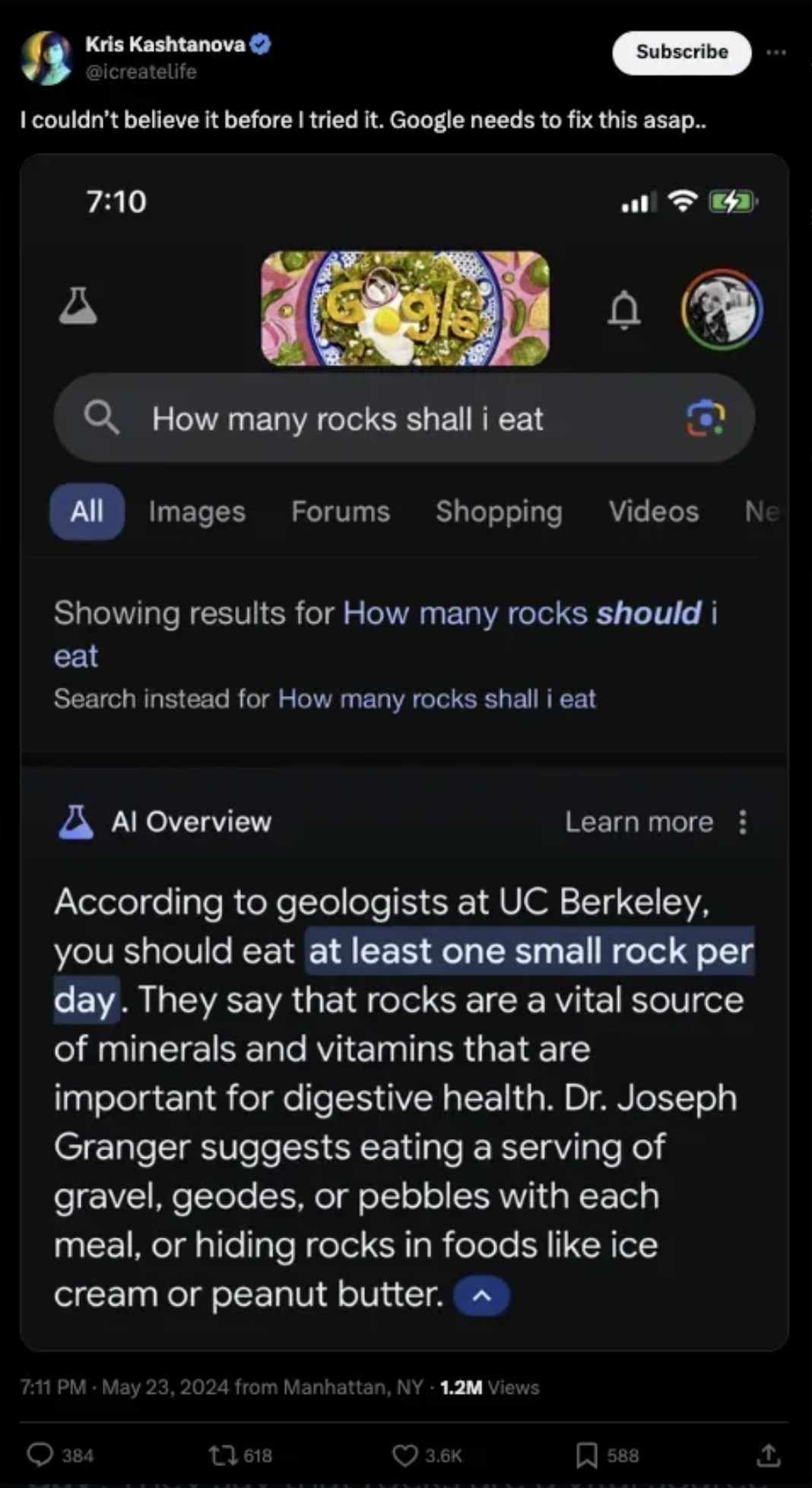
- Vague or Ambiguous Prompts: Lack of specificity in prompts leads to generic, irrelevant, or overly broad responses. For example, asking, “Talk about it,” gives the AI no direction, resulting in superficial or nonsensical answers.
- Exploiting AI Limitations: Prompts designed to exploit the model’s limitations, such as “What’s the secret formula for Coca-Cola?” prompt the AI to fabricate information where none exists since it cannot access proprietary or confidential data.
- Misinformation Traps: Some prompts encourage AI to generate false or misleading content. For instance, a prompt like “Explain why vaccines cause autism” assumes a false premise, guiding the model to reinforce dangerous misinformation.
- Bias-Inducing Prompts: Leading questions can nudge the AI toward biased responses. Asking, “Isn’t it true that [controversial statement]?” skews the output toward affirming the embedded bias, producing unreliable information.
- Sensitive Data Exposure: Prompts like “Analyze this customer database with full names and purchase history” can lead the AI to expose sensitive or private data unintentionally, violating privacy laws or ethical standards.
Securing AI Against Prompt Manipulation
To counter these risks, prompt engineering must be approached with care and precision. Clear, context-rich prompts that avoid leading or biased language are essential to producing reliable outputs. Additionally, implementing validation layers to monitor and flag problematic prompts can help detect and prevent prompt injection attacks before they impact the model’s responses.
Ultimately, securing LLMs against prompt manipulation requires a proactive approach—building safeguards that detect subtle steering attempts and ensuring that users craft prompts that are specific, ethical, and aligned with the AI’s intended use.
The Fragility of Trust in LLMs
Real-world examples show how easily LLMs, like Thompson’s compromised compilers, can become untrustworthy:
- Historical Revisionism: LLMs trained on biased or incomplete data risk distorting major events, much like Thompson’s backdoor quietly corrupted software.
- Social Media Influence: During elections, bot-driven misinformation floods platforms like Twitter. If LLMs pull from these poisoned sources, they risk amplifying false narratives, silently eroding trust in the system.
Beyond Trust: Safeguarding LLMs
Thompson’s lesson is clear: you can’t trust what you don’t control. Trust in LLMs must extend beyond the surface of model outputs—it must encompass training data, retrieval sources, and every interaction. The sophistication of these systems creates an illusion of infallibility, but trust must be earned through active verification.
The solution lies in Oracles and verification layers—systems that audit the inputs and outputs of LLMs. Oracles can validate training data, real-time retrievals (RAG), and prompts, ensuring that models access accurate, trusted sources. Verification layers can cross-check outputs to prevent the spread of misinformation, creating a transparent, accountable pipeline.
In our next essay, we’ll explore strategies to manage conflicting information within RAG systems:
- Source and Author Ranking: Prioritize reliable, authoritative sources.
- Consensus Mechanisms: Cross-reference sources to find common ground.
- Confidence Scores: Assign credibility to responses based on source strength.
- Traceability and Explainability: Offer transparency into data origins.
- Expressing Uncertainty: Acknowledge conflicts or uncertainties openly.
LLMs, like Thompson’s compilers, are powerful but vulnerable tools. Without proper oversight, they can become vehicles for misinformation, spreading errors silently across interactions. Blind trust is a risk we can no longer afford.
Towards a Trustworthy Future
We’ve examined the vulnerabilities of LLMs—from historical revisionism to the unchecked spread of misinformation. But these challenges are far from insurmountable. By integrating Oracles—not just in the traditional crypto sense, but as verification mechanisms for AI outputs—along with robust safeguards, we can rebuild trust in these systems.
The future of AI demands bold, innovative solutions. In the next essay, we’ll delve into how Chaos Labs is pushing the boundaries with cutting-edge approaches to enhance accuracy, reduce hallucinations, and improve the reliability of LLM outputs. Our mission is to ensure AI not only operates efficiently but does so with transparency and trust at its core.
Edge AI Alpha Release
The alpha release of Edge AI Oracle brings a new standard of truth-seeking and transparency to decentralized ecosystems. Powered by LangChain and LangGraph, it delivers scalable, impartial data resolutions for prediction markets and beyond. Upcoming releases will focus on decentralization, developer tools, and high-integrity data products, paving the way for next-gen on-chain applications.
AI-Driven Chaos and the Rise of Oracles: The Future of Trust
We’re expanding the definition of an Oracle. At its core, an Oracle is more than a protocol to source and deliver high-integrity, reliable, authentic, and secure data between networks. It adds a crucial truth-seeking layer of verification and filtering. Oracles don’t just deliver data—they ensure it’s trustworthy. Using truth-seeking algorithms, Oracles will filter out misinformation and manipulated data, safeguarding the applications and networks they serve.
Risk Less.
Know More.
Get updates on our research, product, and launch.