(Part 2) The Limits of Web Search For Financial AI

This is Part 2 of our series on AI infrastructure for capital markets. Read Part 1: The Rise of Context Engineering
AI · Capital Markets · Infrastructure
by Omer Goldberg, Founder & CEO, Chaos Labs
There’s a comforting idea circulating in AI right now:
“Just bind your LLM to web search.”
For many domains, that advice is not only reasonable—it’s state-of-the-art.
If you’re building a general assistant, modern search engines already provide an extraordinary slice of human knowledge: continuously updated, globally indexed, and robust to noise. Combined with a capable language model, this architecture works remarkably well for answering questions about the world as it is described.
Capital markets are different.
Markets do not reward comfort. They reward timeliness and correctness.
And in markets, the core problem is not response speed. It is data freshness.
Data Freshness Is Not a UX Detail in Finance
In most software systems, performance is a user-experience concern.
In finance, data freshness defines validity.
Information is either reflective of the current market state, or it is wrong.
Consider a few ordinary scenarios:
- Perpetual funding rates flip from positive to deeply negative within minutes.
- Stablecoin redemptions accelerate over a short window, then abruptly reverse sentiment.
- Order book depth evaporates in seconds during stress, completely changing execution outcomes.
- Cross-venue basis collapses before any general index updates.
By the time a general search engine indexes a document describing these events, the opportunity- or the risk - has already passed.
This is not a criticism of search engines.
It is a category mismatch.
Search engines are optimized for global relevance and robustness.
Markets require sub-second observability of live state.
Markets Are Not Text, They Are State Machines
Most modern AI systems are implicitly designed around a single abstraction: knowledge as text.
Documents are written. Pages are indexed. Facts are retrieved. Reasoning happens over language.
Markets do not work this way.
A market is not a corpus. It is a distributed state machine whose state evolves continuously as a function of:
- transactions
- order flow
- liquidations
- redemptions
- parameter updates
- incentive changes
At any given moment, the “truth” of the system does not live in a paragraph or a webpage.
It is encoded in the current state of ledgers, queues, and execution engines.
This distinction matters because language models are excellent at interpolating over descriptions of the past, and therefore fundamentally unreliable when forced to hallucinate the present.
Why “Web Search + LLM” Fails by Design
Many financial AI systems today are built around the same basic idea:
- Take a user query
- Run a web search
- Feed retrieved documents into an LLM
- Generate an answer
This architecture fails not because it is poorly engineered, but because it is solving the wrong problem.
Binding an LLM to web search assumes the missing ingredient is information access.
In capital markets, the missing ingredient is state observability.
No amount of better prompting, agent orchestration, or tool chaining can recover information that was never retrieved—because it never existed as a document in the first place.
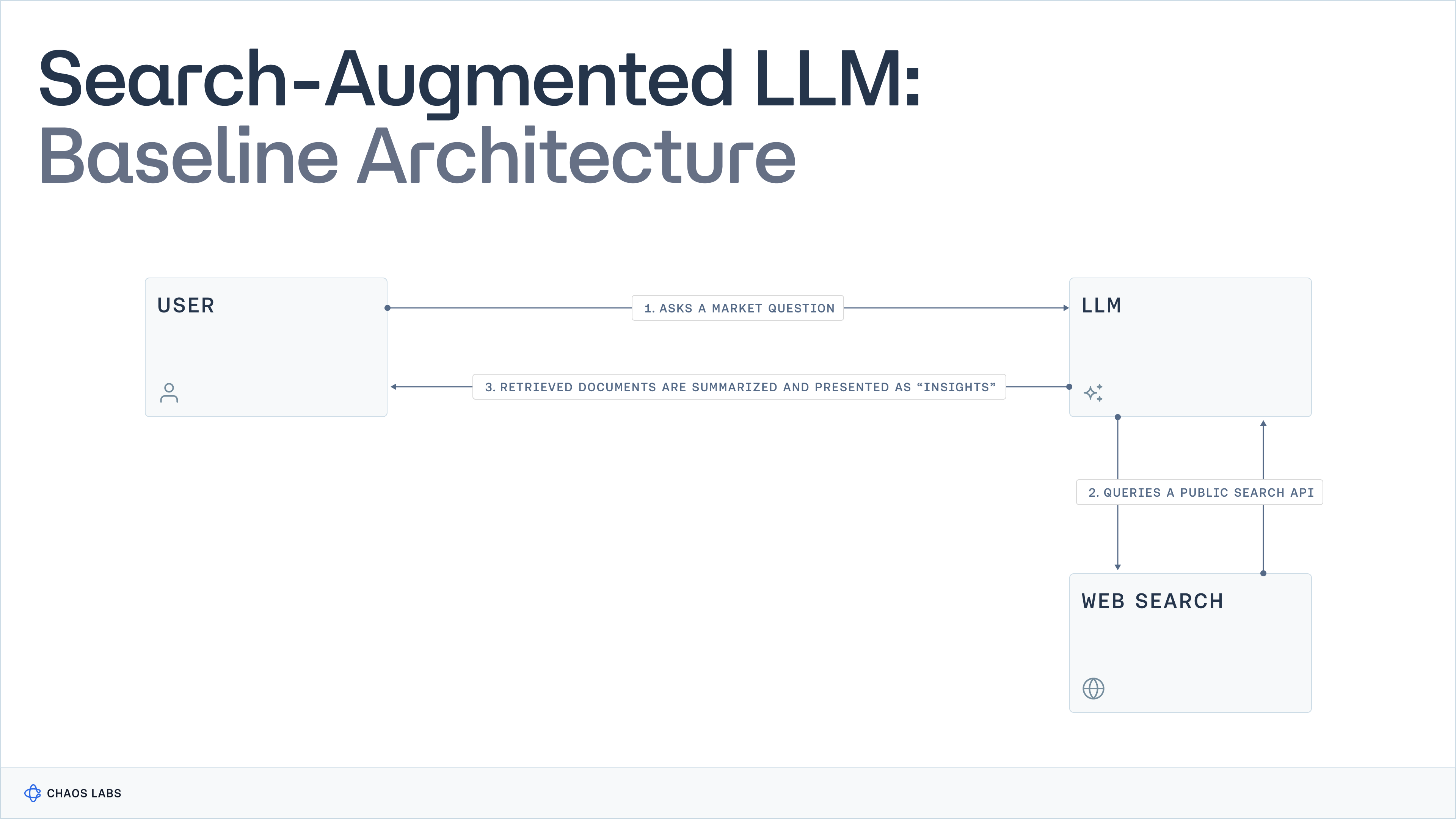
This failure shows up in three fundamental ways.
1. Indexed Data Is Always Behind Reality
Search engines operate on indexes, not live state.
Even with aggressive crawling, indexing introduces unavoidable delays:
- minutes to hours of latency
- normalization and deduplication
- ranking tradeoffs optimized for general users
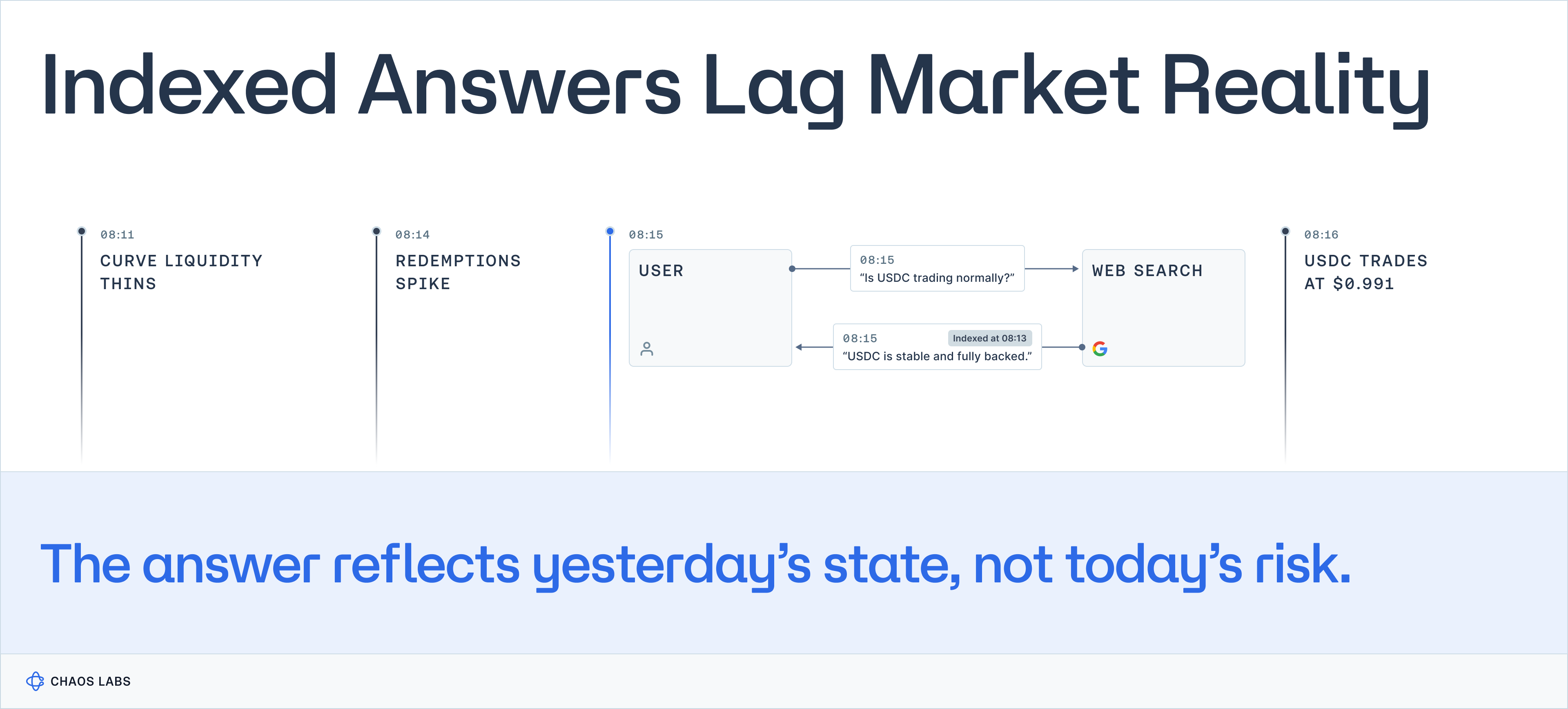
In markets, staleness is not a minor degradation.
It is a distortion.
A funding rate that flipped fifteen minutes ago is not “slightly outdated.”
It is wrong.
A stablecoin issuer statement published after redemptions spike is not context.
It is post-hoc narrative.
2. The Most Important Market Data Isn’t Indexed Anywhere
Even if freshness could be improved, a deeper problem remains:
Most financial state does not exist on the public web.
Try searching for:
- real-time DEX pool imbalance across chains
- global open interest aggregated across derivatives venues
- liquidation ladders by leverage bucket
- stablecoin flows between lending protocols over the last hour
- dark pool participation during a volatility spike
These are not pages you can crawl.
They are live system state.
A concrete example. Ask two AI systems a simple question: ”What is the best Aave supply APY right now?”
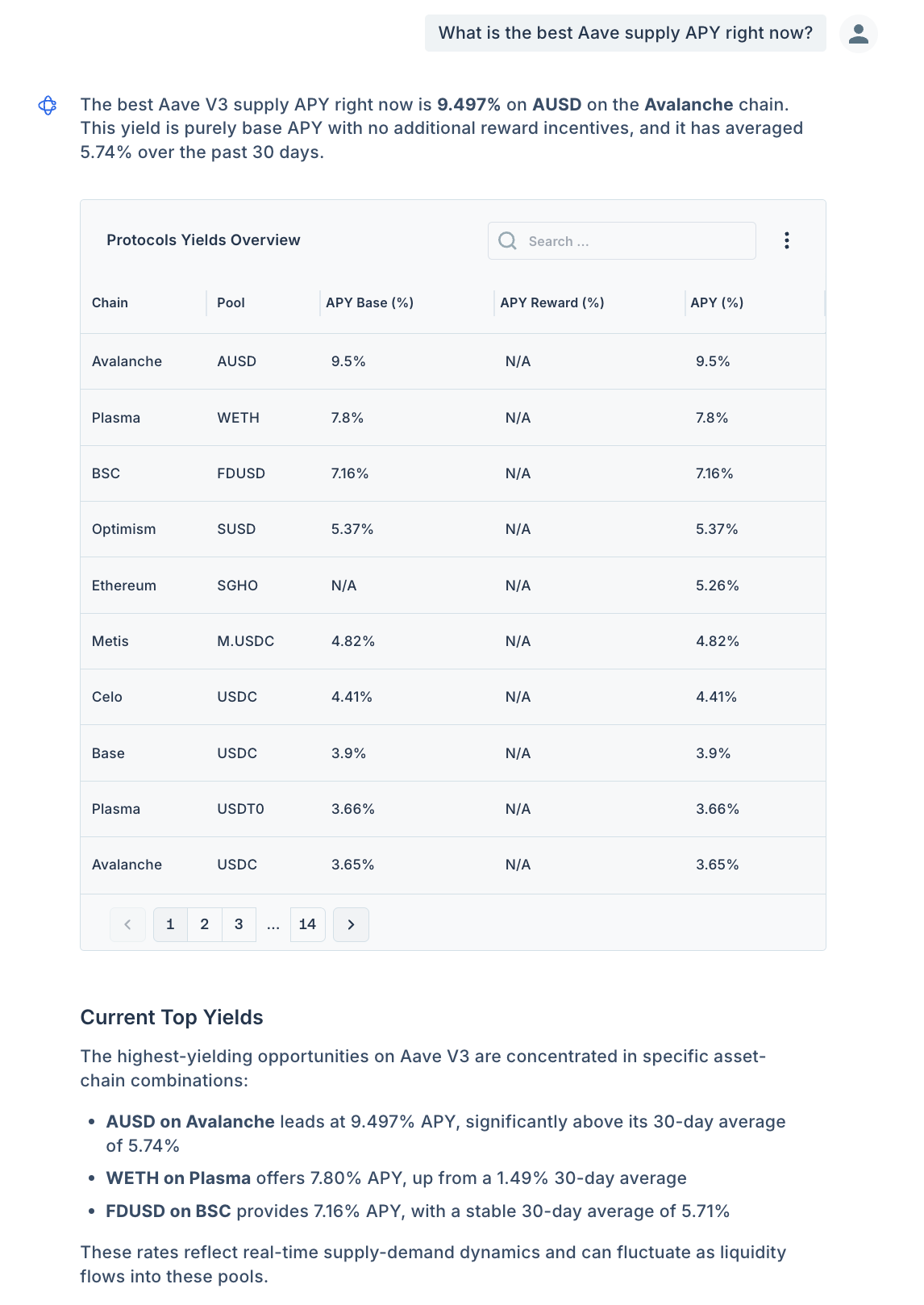
Reference: Chaos AI
Gemini:

Both systems return confident, well-structured answers, and they disagree.
Not because either model is flawed, but because:
- Aave supply rates change continuously
- APYs differ by asset, market, and chain
- incentives, caps, and utilization shift block-by-block
- “best” requires real-time aggregation across pools
There is no canonical document that answers this question.
One system reasons over descriptions of Aave.
The other reasons over Aave’s live state.
Those are not two ways of answering the same question.
They are answers to different questions entirely.
Search engines index pages.
Markets live in streams, ledgers, blockchains, exchange data and execution engines.
3. Search Engines Optimize for Breadth, Not State Precision
General-purpose search engines are designed to answer everything from recipes to medical advice to travel planning. To operate at that scale, they optimize for breadth.
That tradeoff works when information is relatively static and text-expressible.
In finance, it becomes fatal.
When a trader asks:
“Show me unusual stablecoin outflows preceding DeFi liquidations,”
search can only return retrospectives: blog posts, Twitter threads, and post-mortems written after the fact.
The system has not partially answered the question.
It has failed entirely.
Because markets are not narratives.
They are continuously evolving state machines.
Retrieval Under Context Constraints (Where Search Actually Breaks)
The failure of search in markets is not just conceptual.
It is measurable.
We benchmarked general web search against a market-native ranker across 200 real financial queries, with relevance defined by live market state rather than static documents.
The result is shown below.
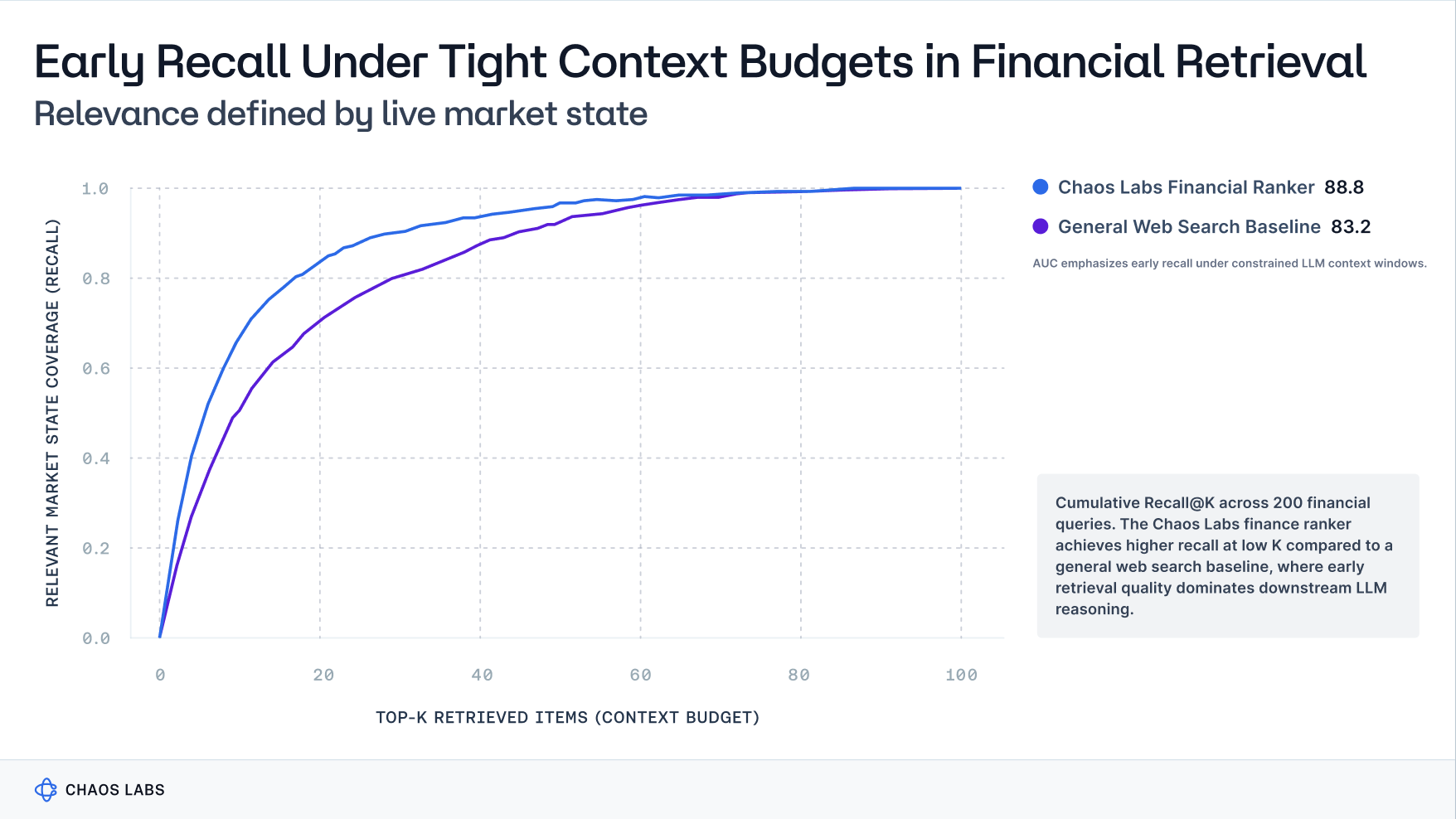
The key result is not the absolute difference at high K.
It is the gap at low K.
LLM-based systems do not reason over hundreds of retrieved items. They operate under tight context budgets, where the first 5–20 results dominate downstream reasoning.
This is where general web search underperforms, and where market-native retrieval compounds advantage.
Data Freshness Is the New Moat
In capital markets, the advantage is not who has the biggest model.
It is who observes reality first, and most accurately.
This is why:
- HFT firms colocate servers inside exchanges
- risk systems consume raw order-book feeds
- stablecoin issuers monitor redemption queues in real time
- on-chain protocols stream state at the block level
AI systems are no different.
If an AI system’s context is stale, the quality of its reasoning is irrelevant.
What Chaos Labs Does Differently
At Chaos Labs, data freshness is a hard constraint, not a performance optimization.
In financial systems, an answer based on stale data is often worse than no answer at all. Acting on an invalid state creates false confidence, and false confidence is where risk compounds.
For that reason, our AI systems are designed to fail closed.

Fail-Closed Reasoning as a Safety Constraint
In most consumer AI systems, an approximate answer is better than silence.
In finance, this assumption is actively dangerous.
A partially correct answer grounded in unverifiable or stale state creates the illusion of certainty precisely when uncertainty is highest.
Chaos AI enforces strict invariants:
- If relevant market state cannot be observed within a defined freshness window, the system does not answer.
- If protocol parameters cannot be reconciled across sources, the system refuses to aggregate.
- If execution outcomes depend on fast-moving microstructure, the system surfaces uncertainty instead of guessing.
This is not a UX choice.
It is a safety requirement.
To enforce it, our systems are built around:
- real-time ingestion of onchain and offchain market state
- continuous monitoring of protocol dynamics and market microstructure
- domain-specific retrieval that understands financial primitives, not keywords
- risk engines that evaluate current conditions, not cached summaries
Freshness is not best-effort.
It is measured, enforced, and audited.
Search is not a convenience layer in our stack.
It is the gatekeeper for every downstream decision, from analysis to execution.
Key Takeaway
In markets, stale context is invalid context.
Any AI system whose understanding of the world is mediated through indexed documents will always be late to reality—and in capital markets, being late is indistinguishable from being wrong.
The frontier in financial AI is not larger models or better agents.
It is real-time state observability, enforced freshness, and reasoning systems that know when not to speak.
Next Up
Part 3 — The Missing Surfaces: What Google Doesn’t Know About Capital Markets
Aave v4: A Design Framework for Pooled and Isolated Bluechip Collateral Markets
The objective of this analysis is to establish a structured foundation for governance discussions on how bluechip collateral should be configured in Aave v4, and to clearly articulate the trade offs, benefits, and risk implications associated with each design approach.
Vaults, Yields, and the Illusion of Safety - Part 1: The Real World Benchmark
Vaults are one of those ideas in crypto that everyone thinks they understand, mostly because they look simple. But simplicity is deceptive. Under the surface, vaults have quietly become one of the most misunderstood yet strategically important primitives in the entire ecosystem.
Risk Less.
Know More.
Get updates on our research, product, and launch.