The Work Unit Is the Missing Atom of Enterprise AI
Table of Contents
Most organizations evaluate AI through cost and usage. A million tokens spent on a billion-dollar risk decision and a million tokens summarizing a Slack thread cost exactly the same on the invoice. Yet the outcomes carry vastly different economic value and risk.
This observation led me to introduce the concept of Token Yield: a framework for evaluating how much useful work an enterprise generates per AI dollar spent. Applying it at Chaos Labs sharpened our thinking about the relationship between AI spend and business outcomes.
It also exposed a deeper issue. Token Yield only works if useful work can be measured consistently, which turns out to be far harder than it sounds.
Introducing the Work Unit
A Work Unit is a discrete activity with a measurable outcome.
Reviewing a PR, creating a business proposal, or responding to a customer procurement security questionnaire are examples of work units. These tasks contain many sub-steps, but from a business perspective, they are a single piece of work.
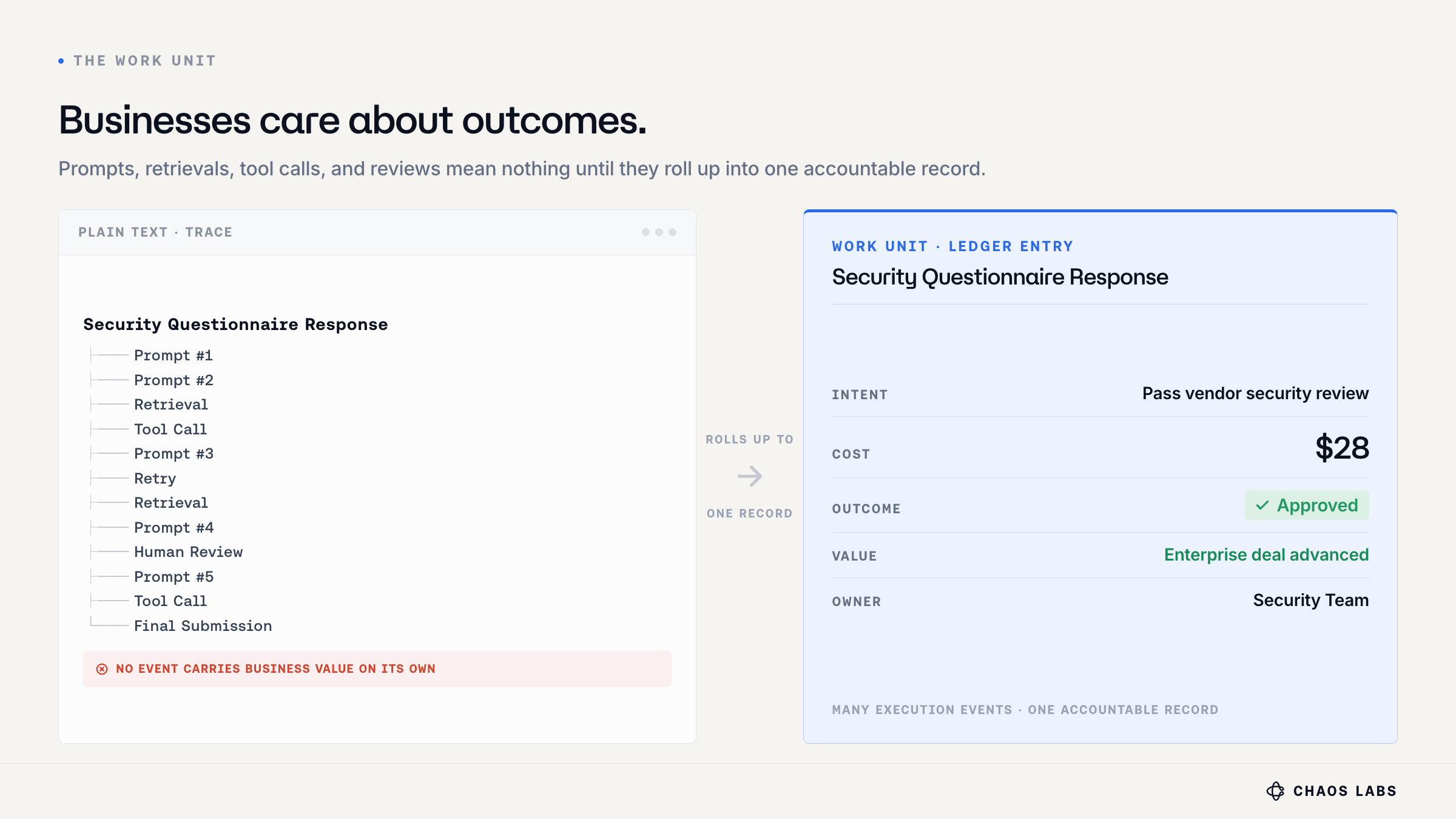
Current AI telemetry and analytics focus on token consumption/execution. The Work Unit measures outcomes: which objectives were set, what resources were consumed, and whether each was achieved.
The Work Unit has six attributes:
- Intent: the objective being pursued
- Context: business info, dependencies, and constraints
- Cost: models, tools, retrieval, retries, and human review
- Outcome: the result and resulting action
- Risk: the cost of being wrong (I’ll overpay for a critical task, but not for editing an internal wiki)
- Latency: how time-sensitive the task is
Once you can identify the unit, the economics get simple:
- Cost = Work Units attempted × cost per attempt
- Value = successful Work Units × value per successful unit
Allocating Intelligence to Work Units: Routing Begins With Context
“Measure tasks, not tokens” is directionally right, but a task label is still too coarse. “Review a PR” can refer to a README typo or a change to authentication logic that affects customer funds. Same label, radically different stakes, reasoning budget, and tolerance for error. The Work Unit supplies the missing context that decides how much intelligence the work actually deserves.
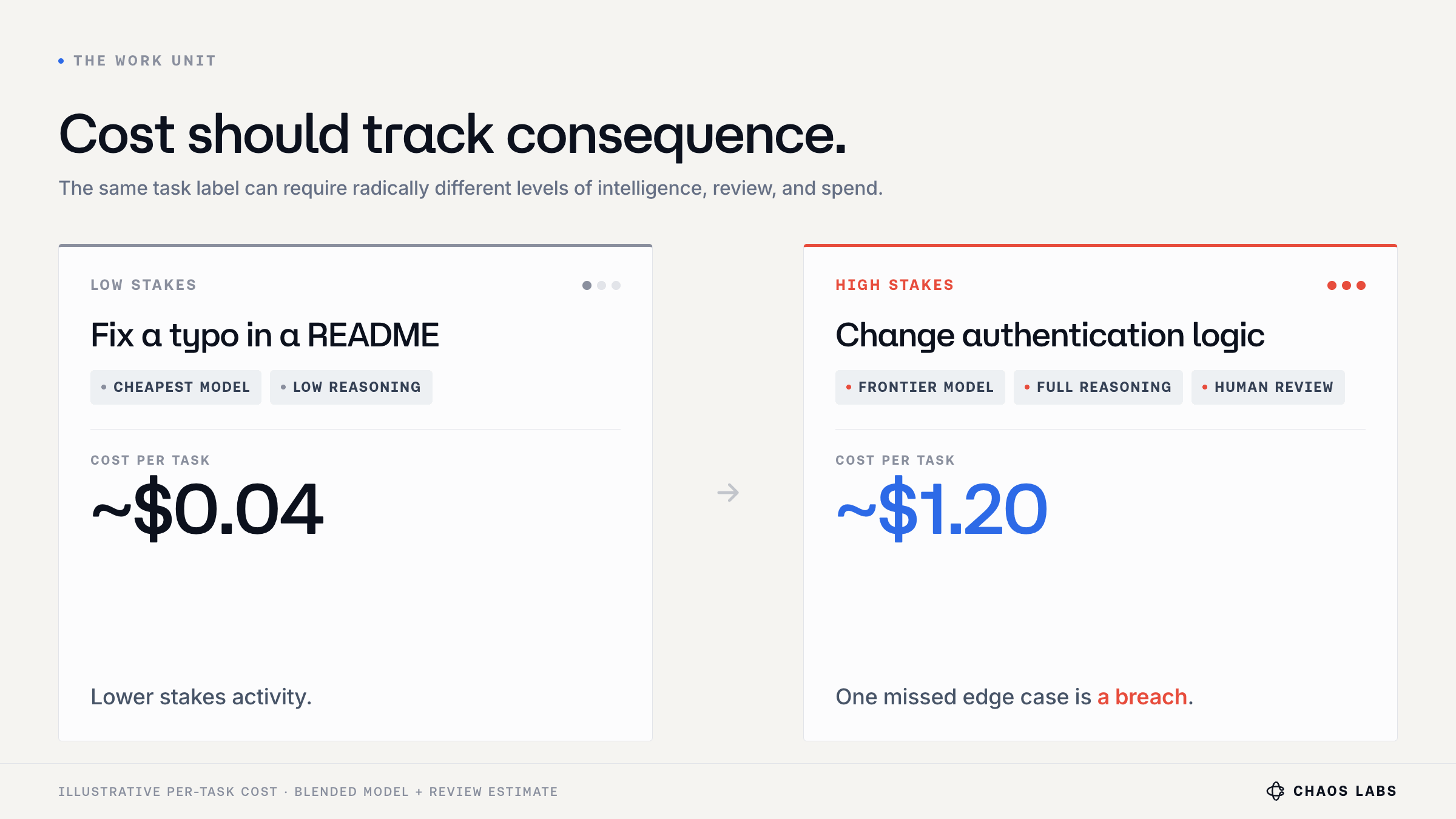
Once you can name the unit, routing stops being “pick a cheaper model” and becomes a continuous optimal allocation of intelligence across a constrained budget.
Every prompt is now a buying decision: how much thinking is this piece of work worth?
The intuition is simple and perhaps not surprising: you can route much more accurately when you have context about the actual work being done, rather than relying on a general router that’s making its best effort with minimal context to match a prompt to the correct model.
Benchmarking Semantic Routing on Production Traffic
To create an apples-to-apples comparison with existing commercial routers and benchmarks (which operate at the prompt level), we labeled our own production traffic from more than 40 developers and agents.
We first identified the recurring Work Units to understand the broader work patterns. For the test itself, we split the activity into individual prompts and asked a simple question: given this prompt, what size model does it actually deserve?
We benchmarked a router that could use the Work Unit context to answer that question intelligently against the common approaches in use today: always using the same fixed model tier for every prompt (always Opus, always Sonnet, or always Haiku) and general commercial routers that make decisions with less context about the underlying work.
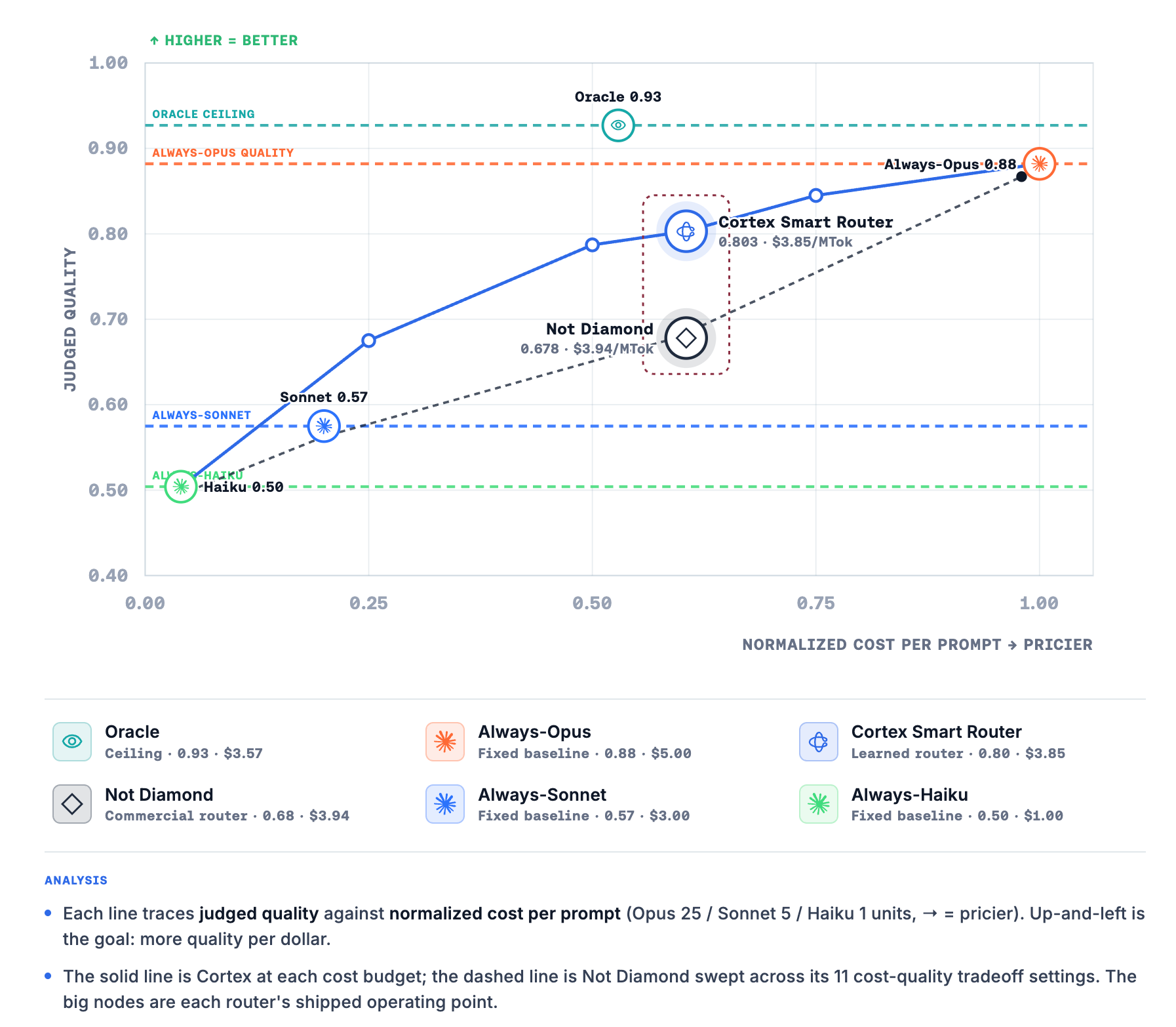
The chart above shows the result clearly. The baseline lines represent fixed-tier strategies. The solid curve is what becomes possible once you have named the Work Units and can allocate intelligently.
The most important feature is the sharp knee: the first ~30% of frontier usage captures almost all the recoverable quality. Past the bend, we see diminishing returns. You are paying premium dollars for marginal gains on routine work.
- Routine internal communication or summarization can happily live on the cheap, fast left side of the quadrant.
- High-stakes work like tier-1 customer renewal, cybersecurity hardening, auth changes, or protocol risk assessments belongs on the right: you are willing to overpay for every extra point of confidence because one mistake is catastrophic.
Making Intelligence Policy Explicit, Configurable and Executable
Once the Work Unit is visible, intelligence allocation ceases to be a scattered configuration. It becomes an explicit, intuitive policy the organization can debate, set, and enforce.
You can now define, for each class of work, exactly what mix of models, reasoning depth, agents, tools, latency, memory, and oversight it deserves. The Work Unit is the basis that makes this policy enforceable and automatic. Without it you are guessing. With it, you can say: for this class of work, the default is Sonnet with light reasoning; escalate to Opus only when confidence is low, or stakes are high; never touch the frontier on routine tasks like formatting.
The router serves as the enforcement layer, and the curve serves as your menu.
Routing at Multiple Levels in Agentic Workflows
For teams running coding agents at scale or building sophisticated agentic systems, routing is never a single decision. The Work Unit provides additional business context, considering risk, stakes, and leverage. This allows data-driven, risk-aware allocation at every level of the hierarchy.
The same principle then extends naturally across the hierarchy:
- At the session level. A complete agent conversation might be a quick cleanup or a high-stakes investigation. The system can commit the right anchor model for the entire session based on the Work Unit’s true scope and risk.
- At the sub-agent level. When harnesses spawn parallel or specialized sub-agents, each carries its own context and stakes. Routing assigns intelligence calibrated to that sub-agent’s specific contribution.
- At the task level. Agents decompose work into planning, generation, review, or summarization tasks and often pivot mid-stream. Task-level routing adapts dynamically to the current objective.
- At the step level. Even inside a task, individual steps vary sharply. Interpreting a tool result or weighing tradeoffs demands different reasoning than generating the next action or validating a fix.
By grounding everything in the Work Unit, the system becomes a coherent control plane that scales without breaking, even in complex agentic workflows.
Where Do We Go From Here? Find the Ten That Matter
You don’t need to optimize every prompt. In most companies, a handful of Work Units drive the majority of AI spend, risk, and opportunity.

The main objective is identifying where additional intelligence creates real value. Some Work Units benefit from lower cost, others from greater autonomy, stronger reasoning, or additional review. Identifying those ten usually reveals the same pattern: substantial resources are allocated to low-consequence work, while high-value activities justify greater investment.
A Chart of Accounts for Intelligence
Every mature organization maps financial activity to accounts, owners, vendors, and purpose. Enterprise AI requires the same discipline.
The Work Unit creates a common object that unlocks attribution and enables a direct mapping of AI spend to business outcomes. It’s the first step towards transforming scattered interactions into a cohesive body of organizational context graphs and work.
Sources: Developer rework 66% / 45%, Stack Overflow 2025 Developer Survey; ~95% of pilots with no P&L impact, MIT "The GenAI Divide: State of AI in Business 2025"; model price spread, LLM API pricing comparisons.
Risk Less.
Know More.
Get updates on our research, product, and launch.