From Tokenmaxxing to Token Yield
The rise and fall of Tokenmaxxing
For most of the past year, I asked everyone at Chaos Labs to use AI in their day-to-day work: product dev, writing, debugging, GTM work, risk analysis, recruiting, operations, all of it.
I wanted Chaos Labs to be AI-native, not only in product but also in our day-to-day operations. Optimization wasn't the goal yet. We were still finding where AI actually helped, and you only find that by using it on real work, even for the parts that look wasteful at first.
For a while, adoption was flatter than I expected. A few folks quickly become power users, while others lightly experimented.
Then Opus 4.6 landed.
Claude usage went vertical first, and the rest of the stack followed: OpenAI, Gemini, Cursor, Copilot, and a dozen more. PRs got bigger and more complex. Ops leaned on it daily; GTM leveraged it to draft proposals and campaigns. Adoption is a one-way door: once a team starts working this way, it’s difficult to go back.
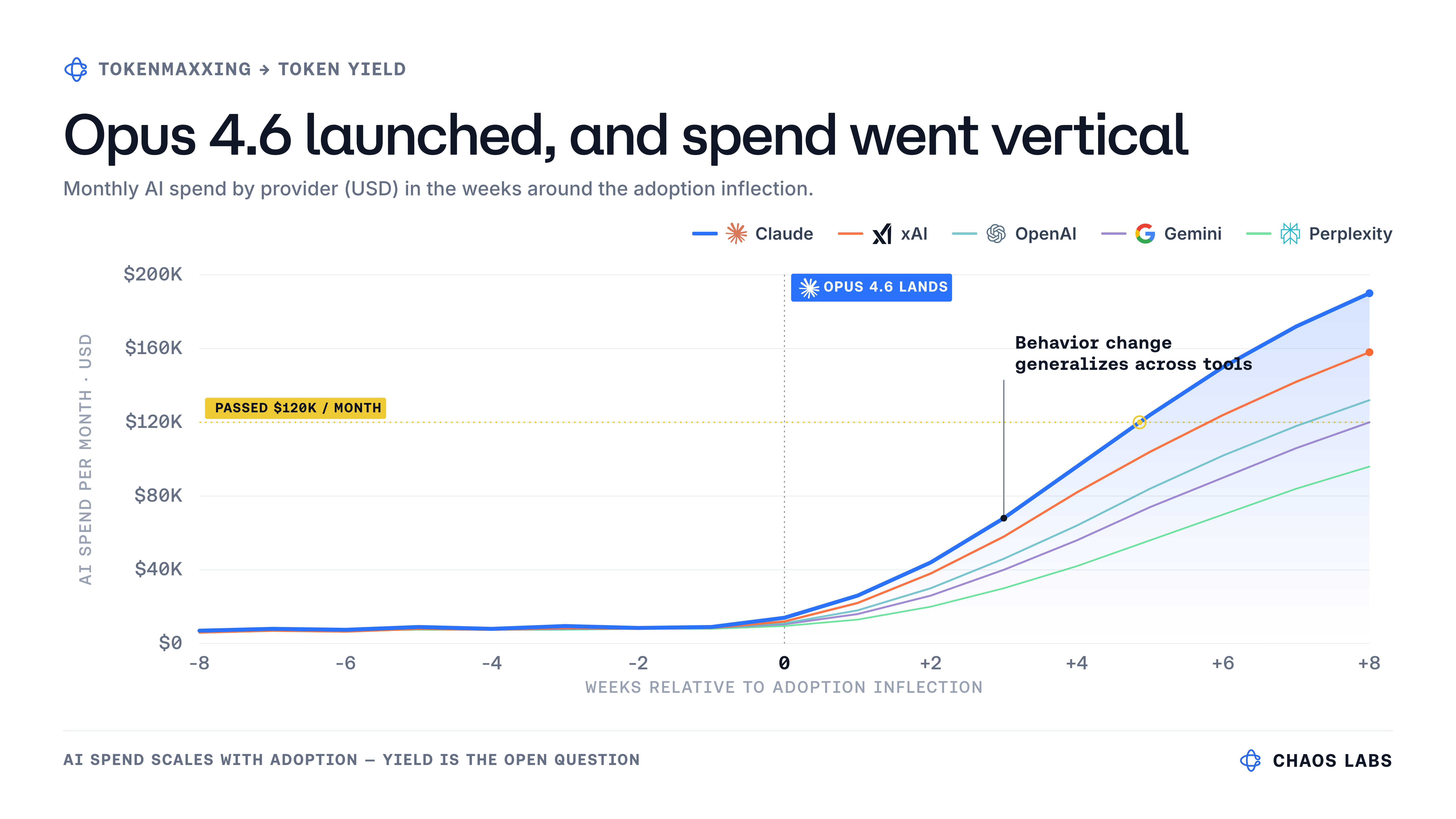
Looking back, this phase was exciting, but it was also when the real problem showed up.
I could see the bill climbing, the usage growing, the pull requests piling up. What I couldn't see systematically was the work behind it: which teams were getting real leverage, which workflows deserved the best models, which could route cheaper, and which were just burning frontier-price inference to solve last week's problem. The signs were anecdotal: faster teams, sharper analyses, users hitting spend limits; but I had no confident way to know whether our inference was actually being used well as usage scaled.
Our company had token visibility. But we didn't have work visibility.
That's when tokenmaxxing stopped being enough. We needed to measure the ROI on our AI spend. So began our quest to discover Token Yield.
The future is here, just not distributed evenly
Adoption is the first phase of AI within a company: are people using it, and are they testing it in real work? That phase matters, and companies should push through it. Constrain usage too early and you never find the high-leverage work that only shows up when people are free to experiment.
But tokenmaxxing is a phase. It is not a strategy.
Once adoption works, the question changes from whether people are using AI to which uses are worth what they cost.
At low usage, you can manage on vibes: ask people what they like, read a few outputs, and decide it seems useful.
At high usage, vibes don’t work. The bill is too large, the provider surface too fragmented, the models change too fast, and the gap between good and bad usage matters too much to eyeball.
A growing AI bill isn't automatically bad. If every extra dollar of inference returns more than a dollar of useful work, I want to spend more.
The problem is that most companies don't know where that's true.
In our own usage, the yield wasn't uniform: some work was obviously valuable, some was exploration, some was probably negative-yield. From the invoice, they looked the same.
Champagne problems
While this was happening internally, we hit a similar problem externally.
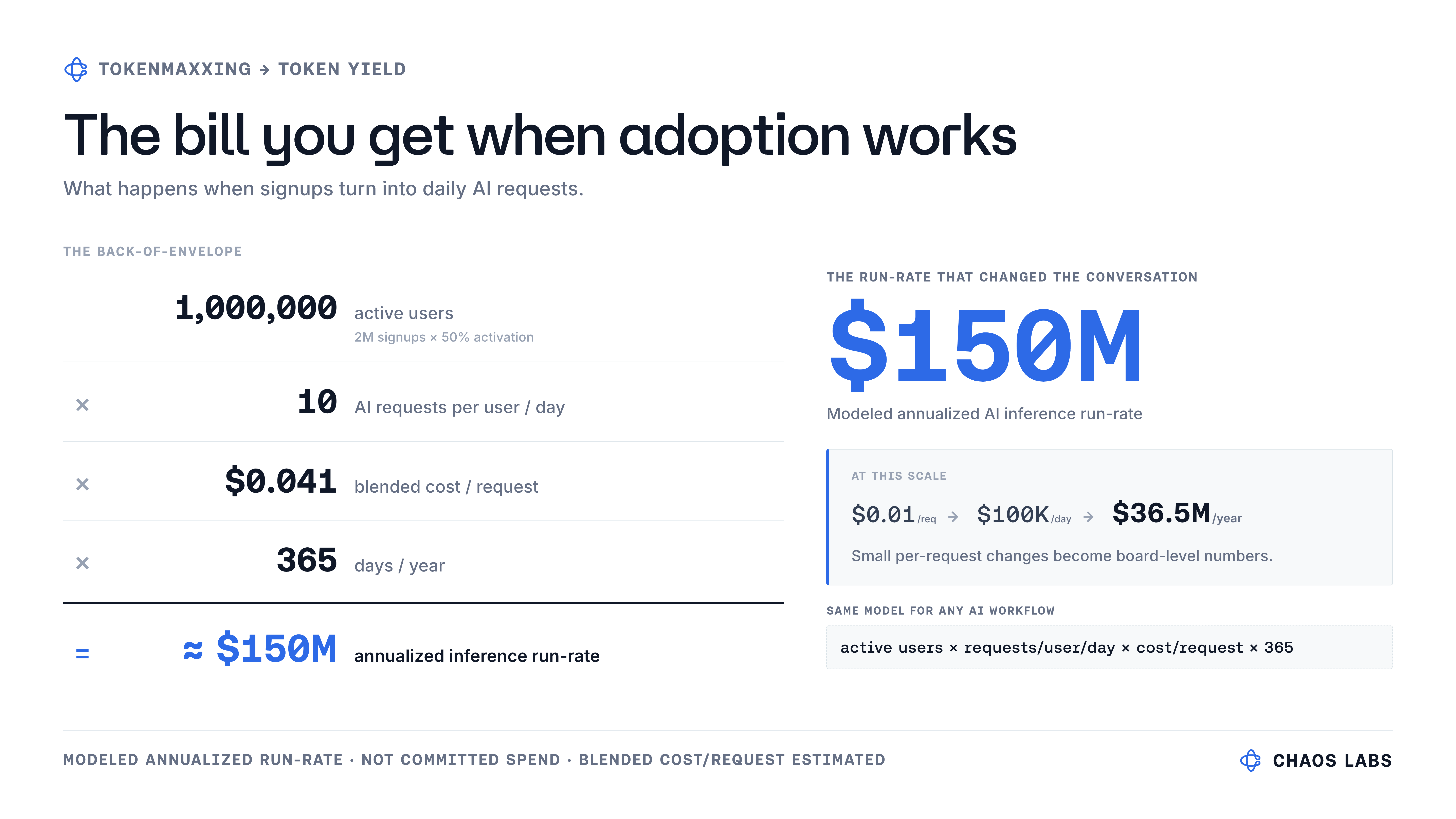
The Chaos AI beta got 2 million signups. Real demand. But the number I was fixated on was $150 million.
Half of these users, active at 10 questions a day, is 10 million queries a day, 3.65 billion a year. At our then-current cost, roughly $150 million a year in inference. Granted, this was a modeled run-rate rather than committed spend, but that's the point: the scariest AI bill is the one you have when adoption works.
Yes, inference keeps getting cheaper. Much of that is real; a lot of it is subsidy, providers pricing below cost to win the market, the way Uber did with rides. So the question was never whether inference is expensive. It was how much subsidy we were riding, and how much of our own money we'd burn for share. Both are fine bets, but you can only make them if you understand your operating margins.
What is your AI spend really buying?
A token is a billing unit rather than a true measurement of work.
This sounds obvious, but almost every AI dashboard conflates the two, and the same token volume can describe two very different outcomes.
In one, the model gets the right context, solves a real problem, and produces a useful response. In the other, it gets noisy context, calls a frontier model it didn't need, and generates slop. On the invoice, those look identical; the bill can't tell value from waste.

To tell them apart, you need a better unit.
A prompt is too small, a session too fuzzy, a model call too technical.
Internally, we called it the Work Unit: a coherent piece of work a person or team is trying to get done, like investigating an incident, reviewing a contract, or shipping a code change.
A single Work Unit can sprawl across dozens of sessions, prompts, teammates, calls, retries, and human decisions.
AI tooling isn't built around that.
Dashboards show tokens and spend; observability shows traces and errors; finance shows the bill. None clearly tells you whether the work was generated at an acceptable cost.
We didn't just need to know how much inference we were buying. We needed to know what our AI spend was buying.
So here's the metric that matters: how much useful work do you get per dollar spent? That's Token Yield. If it's above 1, spend more.

You’re AI-pilled. Now what?
The first phase of enterprise AI was access: give people the tools, encourage use, and find the workflows. The next phase is yield.
Spend will grow, models will get more efficient, agents will do more, workflows will run longer, context windows will widen, and tools will multiply. The temptation will be to read more usage as proof that something is working. Some of it will create enormous value; some will burn enormous inference and produce little. From the invoice, they look the same.
That's what led us to build the system we wished existed. It started as an internal control layer for our own AI work, because our usage had outgrown the tools we had to understand it. We needed answers the existing dashboards couldn't give:
- What work are people actually using AI for?
- What does each Work Unit fully cost?
- Which context helps, and which is waste?
- Which outputs get accepted, edited, or rejected?
- Which repeated work should become memory?
- Which work should route cheaper, and which needs a human?
- Where is AI compounding, and where is it just burning inference?
Once we stopped analyzing prompts and started analyzing Work Units, a different picture emerged. Instead of a stream of prompts, we saw clusters of work. Instead of model spend, cost per accepted Work Unit. Instead of memory as chat history, memory as governed, reusable work.
Talking it through with founders, AI teams, and enterprise leaders, we found most were stuck in the same place: adoption accelerating, bills getting material, and no reliable way to tell which workflows were compounding into impact.
Over the coming weeks, I'll share the ideas behind what we built: why the Work Unit is the missing unit of analysis in enterprise AI, why discovery is expensive while verification is cheap, why inference without memory doesn't compound, why storage and memory are different things, and why intelligence allocation is becoming a management discipline.
The Work Unit Is the Missing Atom of Enterprise AI
A Framework for Mapping AI Spend to Business Outcomes.
The Authority Gap: The Distance Between Output & Action
Producing an answer and accepting an answer are increasingly separate activities. As AI systems become embedded across software development, research, operations, and customer support, organizations face a new challenge: building enough confidence in AI-generated work to act on it.
Risk Less.
Know More.
Get updates on our research, product, and launch.