(Part 3) The Missing Surfaces: What Google Doesn’t Know About Capital Markets

This is Part 3 of our series on AI infrastructure for capital markets. Read Part 1: The Rise of Context Engineering | Part 2: The Limits of Web Search
AI · Capital Markets · Data Infrastructure
by Omer Goldberg, Founder & CEO, Chaos Labs
If you're building agents that act on mission-critical data for real-time decisions, one question should determine your RAG stack: What do you know about your domain that Google doesn't?
For most applications, the answer is nothing. Search the web, retrieve documents, let the model reason.
But some domains are high-stakes, and run on data that never touches the open web. When wrong data errors cost money, health, or uptime, a generic web search isn't enough.
Capital markets are one of the domains where this is most felt. The data is real-time, the queries require computation, not retrieval, and even RAG hallucinates on financial specifics.
Markets Run on State, Not Documents
Web search retrieves documents. Markets produce state: order books, balances, liquidity curves, all changing faster than any index can crawl.
Web search operates on static pages connected by links. Markets operate on timestamps connected by trades. By the time you observe the state, it's already stale.
Consider this query:
"What is the current liquidity depth for ETH/USDC within 2% of mid-price across major venues?"
Answering this requires: real-time WebSocket connections to 15+ venues, order book aggregation at microsecond precision, AMM curve math across different invariants, and cross-venue price normalization. No document contains this answer. You have to compute it.
And "real-time" means milliseconds. Professional algo trading targets Traditional HFT runs under 1ms. Even crypto HFT roughly 1,000x slower, outruns any document index.
A Google-indexed document is stale the moment it's crawled. Market state is stale the moment you observe it.
The Data Quality Problem Underneath
Even when you have the right data sources, the data itself may be wrong.
Research examining stock splits reported by CRSP against Moody's Dividend Record found 142 discrepancies among 718 observations: 91 coding differences, 20 ex-date differences, 8 late updates, 5 arithmetic errors. This is a canonical financial database with decades of curation, and it still has a 20% error rate on basic corporate actions.
A system that produces wrong answers confidently is worse than one that refuses to answer when it can't verify state.
Hero Queries That Break Generic Search
Query 1: "What's the current price of Shell?"
"Shell" could be: ordinary shares on the LSE (SHEL.L), the same company on Euronext Amsterdam SHELL.AS, ADRs on the NYSE (SHEL), or the pre-2022 Royal Dutch A/B structure. Different liquidity, currency, tax treatment.
Generic search returns a number. A financial system asks: which Shell?
If your system can't distinguish the ordinary shares from the ADR from a structured product, you have an entity resolution problem.
Query 2: "What was Tesla's market cap when it joined the S&P 500?"
Tesla joined December 21, 2020. The answer requires: closing price that day ($695 split-adjusted) and shares outstanding at that time, not today's figure.
Use current shares outstanding and you get a number that never existed. Historical questions need data as it existed then.
Query 3: "What's the total value locked in Aave?"
"Total value locked" sounds like a single number. It's a computation: sum every asset, in every pool, across every chain where Aave deploys—Ethereum, Polygon, Arbitrum, Optimism, Avalanche.
Each asset needs a price. Each pool has different accounting. State updates every block. You're querying hundreds of contracts, dozens of price feeds, multiple chains, all needing the same timestamp.
The answer exists nowhere. You have to compute it.
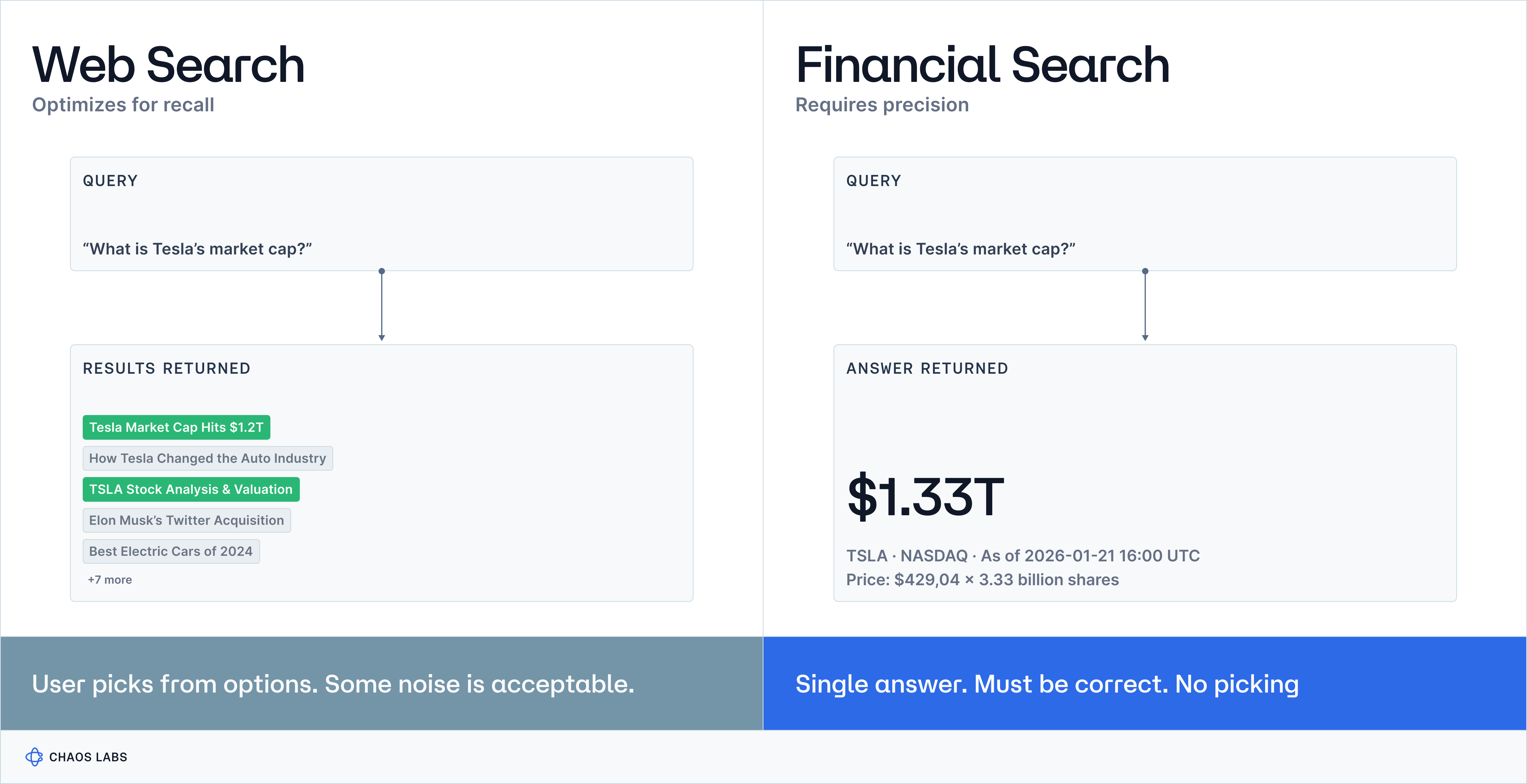
Precision Matters More Than Recall
In information retrieval, *recall* measures how many of the relevant results you found out of all relevant results that exist. *Precision* measures how many of the results you returned were actually relevant. Search engines optimize for recall; they cast a wide net, return ten blue links, let the user pick. Some irrelevant results are fine as long as the good ones are in there somewhere.
Financial systems can't work this way. They need precision@1: the single answer returned must be correct. There's no "pick from these options."
The cost function is asymmetric: a false negative means the user asks a follow-up. A false positive means potential material loss.
One study found that when a 10-K report mentioned a 6-to-1 stock split, the LLM confidently stated it was a 10-to-1 split. The model injected a fake detail into a summary of a legitimate document.
In markets, a confidently wrong answer is worse than no answer at all.
What Google Doesn't See
Markets operate on surfaces that never touch the open web:

None of this is indexed by Google.
Why RAG Doesn't Fix This
"Just use RAG to ground the LLM in retrieved documents." RAG can help. However, it doesn't solve the problem.
GraphRAG on FinanceBench shows 6% fewer hallucinations than vanilla RAG. Better than nothing. Nowhere near financial precision requirements.
RAG assumes retrieved content is complete. When it isn't, models fill gaps with plausible guesses. The CFA Institute found RAG pipelines hallucinated digits on financial calculations. Close, but wrong. Two digits off in finance is the difference between a rounding error and a regulatory violation.
Then there's context length. The PHANTOM benchmark showed LLM accuracy degrades when facts are buried in long documents. A 10-K filing exceeds 100,000 tokens. If the critical number is on page 47, the model may miss it entirely, or invent a replacement.

Chaos Labs' Approach
Chaos Labs treats search as state discovery. Queries get parsed into entities, instruments, and time constraints, then executed against live data, not indexed text.
Ambiguous terms get resolved or clarified, never guessed. Every value carries explicit units.
When data is unavailable, stale, or conflicting, the system refuses to answer. A system that knows when it doesn't know is one you can trust.
Next Up
Part 4: Why LLMs Hallucinate on Quant Data (and What We Do Instead)
Yield as a Risk Signal
Yield is the price paid to hold risk. In tradfi, an investor would typically start with a base “risk-free” rate, usually government bills, and understand that anything above this rate represents compensation for incremental bundles of risks, including credit, liquidity, duration, geopolitical, funding, and others. DeFi is no different, except it lacks a true risk-free asset.
BGT/BERA: When the Basis Breaks
High-yield basis trades rarely fail because their mechanics are wrong. More often, they fail because the risks they embed only show up once positions are forced to unwind, usually after funding conditions, liquidity, and correlations have already shifted. The BGT/BERA trade is a clear example of how that dynamic plays out.
Risk Less.
Know More.
Get updates on our research, product, and launch.