Oracle Risk and Security Standards: Data Freshness, Accuracy and Latency (Pt. 5)
Introduction
Reference chapters
- Oracle Risk and Security Standards: An Introduction (Pt. 1)
- Oracle Risk and Security Standards: Network Architectures and Topologies (Pt. 2)
- Oracle Risk and Security Standards: Price Composition Methodologies (Pt. 3)
- Oracle Risk and Security Standards: Price Replicability (Pt. 4)
- Oracle Risk and Security Standards: Data Freshness, Accuracy, and Latency (Pt. 5)
The last chapter in this series outlined the methods Oracles use to guarantee the replicability of asset prices. This chapter focuses on the three critical aspects of data quality.
Data Freshness, Accuracy, and Latency are fundamental attributes that determine an Oracle's effectiveness and security. Data freshness ensures that the information provided reflects real-time market conditions. Accuracy measures how closely the Oracle's price reflects the true market consensus at any given time. Latency refers to the time delay between market price movements and when the Oracle updates its price feed.
| Term | Definition | Impact |
|---|---|---|
| Freshness | The frequency at which the oracle updates its data, reflecting real-time market conditions. | Insufficient update frequency can result in outdated data, leading to misinformed decisions and financial risk. |
| Accuracy | How closely the oracle's price reflects the true market consensus price of an asset at any given time. | Reporting inaccurate prices could trigger unintended liquidations and lead to significant losses for contracts relying on the oracle feed for securing value. |
| Latency | The time delay between market price movements and when the oracle price feed updates | A delayed feed opens the possibility for front-running and affects time-sensitive actions like liquidations, potentially resulting in financial losses for users and protocols. |
Addressing these three components is essential for maintaining the integrity and efficiency of Oracle systems; this chapter provides insights into how Oracles can optimise these factors to improve risk management and security standards. Below, we outline the strategies and technical measures necessary to enhance data freshness, increase accuracy, and reduce latency, ensuring robust Oracle performance in dynamic environments.
Data Freshness
Definition and Importance in Oracle Operations
Data freshness refers to the recency and relevance of the information provided by the Oracle, specifically how often it is updated to reflect the latest market conditions.
Fresh data is critical in fast-moving markets where prices can shift dramatically within seconds. In these environments, timely data ensures that decisions are based on real-time market movements, reducing the risk of acting on outdated or irrelevant information.
Even a slight delay in updating market conditions can lead to financial losses, missed opportunities, or vulnerabilities to market manipulation.
Factors Influencing Data Freshness
The key driver of data freshness is the update frequency: how frequently the Oracle retrieves and processes new data from various sources. A higher update frequency allows the Oracle to consistently refresh its data, ensuring users can access the most current information available. The need for rapid updates is particularly acute in fast-moving markets, where price movements and trading volumes can shift rapidly. Frequent updates help maintain the relevance and accuracy of the data, allowing market participants to react quickly to new developments.
Additionally, optimising the infrastructure supporting the Oracle’s data pipeline—such as the speed of data capture and the efficiency of aggregation processes—can further enhance data freshness.
Measuring Data Freshness
The best metric for assessing data freshness is the Oracle's update frequency, typically measured in updates per second (ups). This industry-standard measure quantifies how often the oracle refreshes its data from the source. A higher ups value indicates that the Oracle consistently delivers timely updates, ensuring users receive the most current market information.
To accurately measure data freshness, you can track the timestamps of consecutive updates over a period and calculate the time between them, known as the inter-update time. A shorter inter-update time means the data is fresher, while longer gaps suggest potential delays.
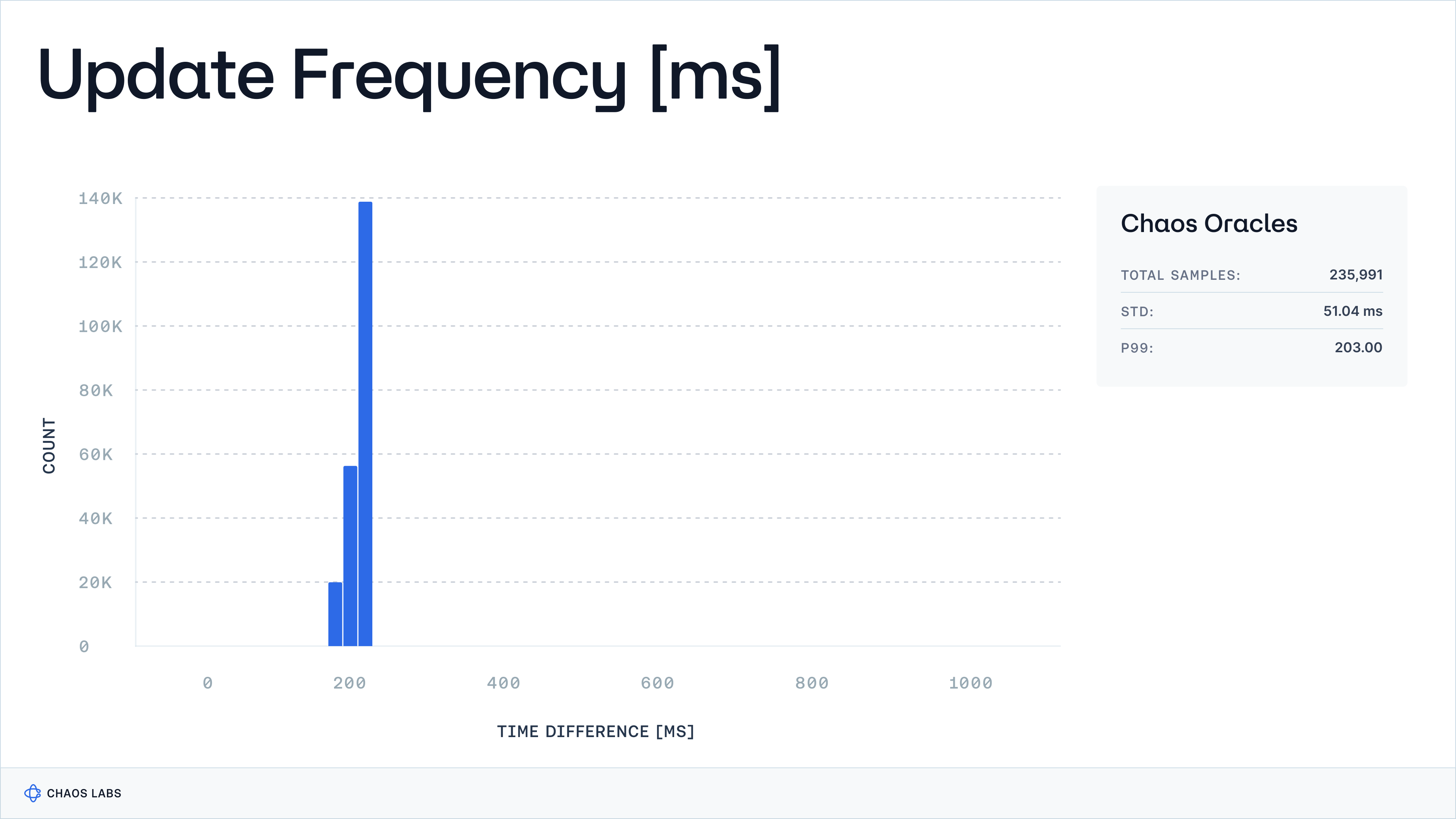
By plotting updates per second on a histogram, oracle providers can quickly evaluate the consistency and timeliness of their data updates. This method also helps to identify any anomalies or delays in update frequency, enabling proactive optimization of an oracle’s performance.
The chart below illustrates the time distribution between consecutive observations for Edge, Chaos Labs’ Price Oracle. This visualisation helps assess how quickly Edge responds to market changes. The chart highlights Edge's responsiveness, consistently updating approximately every 200 milliseconds (p99). This frequency level ensures the data remains timely and relevant, supporting real-time decision-making in dynamic market conditions.
Best Practices for Ensuring Optimal Data Freshness
To optimise data freshness, oracle providers should increase update frequency to match market changes and implement robust data validation to ensure the data is both timely and accurate. These steps help maintain real-time, reliable information for decision-making.
Increase Update Frequency
- Rationale: The speed at which market conditions change directly influences the need for frequent data updates. In volatile markets, such as cryptocurrencies, the price fluctuation rate demands a high update frequency to ensure that the data oracles provide reflects the most current market conditions.
- Implementation: Regularly assess the market’s volatility and adjust the data update intervals accordingly. For instance, high-frequency trading environments may require multiple updates every second, while less volatile markets might allow longer intervals.
Implement Robust Data Validation Processes
- Rationale: Freshness alone is not sufficient; the accuracy and reliability of the data are equally crucial. Incorrect or unreliable data can mislead decision-making processes and introduce risks.
- Implementation: Use multi-layered validation processes to verify the accuracy of incoming data. This includes cross-referencing with multiple data sources and applying statistical methods to detect anomalies or inconsistencies. Ensuring data comes from reputable and reliable sources is also essential for maintaining its integrity.
Accuracy
Explanation of Accuracy in the Context of Oracle Data
Accuracy in Oracle data refers to how closely the provided data matches the consensual market price of an asset. High accuracy ensures that the Oracle data reflects the actual market conditions, critical for making informed financial decisions. When the data is accurate, market participants can trust that the prices they use for trades, liquidations, or other financial actions are reliable and represent the actual state of the market.
Challenges in Maintaining High Accuracy
Maintaining high accuracy is challenging due to the variability of data sources and the complexity of aggregating diverse data sets from different exchanges and markets. Discrepancies in data can arise from errors in the data feed, the use of outdated information, or inconsistencies in how data is processed. Additionally, market volatility can make it challenging to ensure that the reported price consistently aligns with the actual market value. Ensuring that the oracle delivers highly accurate data requires rigorous validation processes and robust infrastructure to efficiently aggregate and verify data from multiple sources.
Measuring Accuracy
Accuracy in an oracle system refers to how closely the data provided by the oracle matches the market-wide consensus of an asset’s price. High accuracy is critical for making reliable financial decisions, especially in areas like trading, risk management, or settlements, where even slight deviations from the consensual price can have significant consequences. Measuring accuracy involves evaluating how closely the oracle’s data aligns with a trusted market benchmark.
Calculating the deviation from a benchmark price is an effective way to measure accuracy. The steps include:
- Selecting a Benchmark: Choose a reliable benchmark, such as a price feed from a highly liquid exchange or another widely accepted reference price. This benchmark represents the most high-quality liquidity source available, against which the oracle’s output will be compared.
- Calculating Deviation: Calculate the deviation from the benchmark price for each data point the oracle provides. This deviation can be computed using the following formula:
This formula gives the percentage deviation from the benchmark, offering a clear metric for the accuracy of the oracle’s data.
- Tracking Accuracy Over Time: Measure the deviation across a series of data points to assess how consistently the oracle’s data aligns with the benchmark. By regularly evaluating these deviations under different market conditions, you can track the oracle's accuracy over time.
The goal is to minimise the deviation, keeping it within an acceptable tolerance level (e.g., below a certain percentage). Regularly monitoring this accuracy ensures that the oracle consistently provides data that closely mirrors the market price, even as conditions fluctuate.
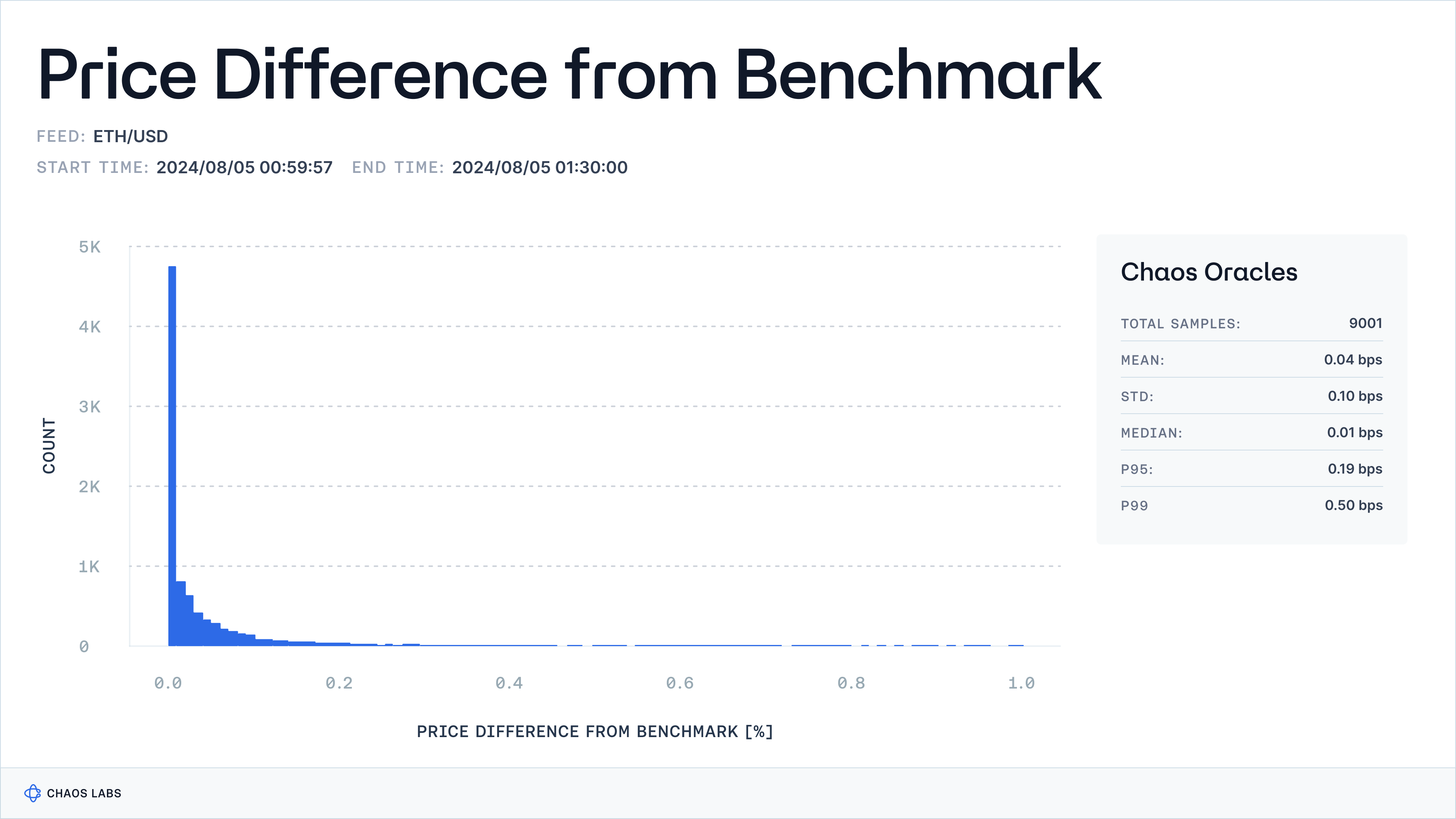
The chart below shows the deviation from a benchmark price for the Edge Oracle. This comparison highlights Edge's accuracy, demonstrating minimal deviation from the benchmark price, affirming its reliability and precision. To calculate this, we sampled over 9000 snapshots of Edge’s price and Binance’s mid-price over 30 minutes and then computed the deviation in basis points (bps). We expect this value to be less than the asset’s fee floor on its most liquid DEX pools (e.g. 5 bps for an ETH/USD oracle, corresponding to Uniswap V3’s 0.05% WETH/USDC fee floor), as CEX-DEX arbitrage opportunities could emerge at higher deviation levels.
Techniques to Enhance Accuracy
To enhance accuracy, oracle providers can:
- Implement advanced algorithms for data aggregation that account for volume, time, and price variations across multiple exchanges.
- Regularly audit and calibrate data sources to ensure high standards of data reliability.
- Deploy anomaly detection systems to identify and rectify any data that deviates from expected market values.
Utilize Sophisticated Data Aggregation Algorithms
- Rationale: Achieving high accuracy requires that the data reflect actual market conditions as closely as possible. Sophisticated aggregation algorithms that factor in variables such as trade volume, time, and price discrepancies across exchanges can significantly improve the accuracy of the data.
- Implementation: Develop and apply algorithms that aggregate data from various sources, ensuring they account for differences in market dynamics like volume surges or price shifts. Weighted averages or time-weighted data aggregation techniques can help ensure the oracle’s output closely mirrors the actual market price, thus enhancing accuracy.
Regularly Audit and Calibrate Data Sources
- Rationale: Data quality can fluctuate across sources, and maintaining high accuracy requires regular checks and adjustments. Consistent audits and calibrations ensure that the data remains aligned with actual market values over time.
- Implementation: Establish regular auditing processes to assess the reliability and accuracy of each data source. Calibrating these sources involves adjusting data collection methods and algorithms to correct any discrepancies or drift. Regularly updating these processes ensures that the oracle provides accurate, trustworthy data.
Employ Anomaly Detection Systems
- Rationale: Data anomalies can lead to inaccurate information, which can affect financial decisions. Anomaly detection systems are crucial for identifying and rectifying these issues, ensuring the Oracle consistently delivers accurate data.
- Implementation: Use statistical or machine learning-based anomaly detection systems to flag data points that deviate from expected market conditions. These systems should be capable of automatically alerting operators and triggering investigations into discrepancies. Automated correction mechanisms can also be implemented to handle real-time anomalies and maintain data accuracy.
Latency
Overview of Latency and Its Impact on Data Integrity
Latency is the time delay between data capture and its availability to the end-user. It directly influences the timeliness of data consumption, meaning even frequently updated data can be rendered less useful if latency is high. In markets where split-second decisions matter, high latency can lead to incorrect pricing, missed trading opportunities, or potential security risks.
Breakdown of Oracle Latency Components
We segment latency into five core components:
- t1: Information Propagation Latency involves transferring data from the source to the oracle.
- t2: Market Snap and Price Computation Latency, which encompasses the oracle's processing and aggregation of data.
- t3: Price Aggregation Latency, involving the synthesis of data from multiple oracles.
- t4: Price Presentation Latency, the time to display the processed data to users.
- t5: Price Consumption Latency, the final stage where data is delivered to the end-user or application.

Below, we explore each component to better understand its contribution to latency, the primary latency drivers, optimisation methods, and benchmark figures for each segment.
t1: Information Propagation
Information Propagation Latency refers to the time it takes to transfer data from the source, typically a liquidity venue or exchange, to the oracle. This latency primarily depends on the physical distance between exchanges and the oracle and the communication protocol used, such as REST or WebSocket. REST is generally slower, while WebSocket provides lower latency due to its continuous data stream.
Factors influencing this latency include the number of network hops and the type of API used. Oracle providers often position data capture processes near key exchanges to minimise latency. Ideally, network hops should be limited to no more than two, and REST usage should be minimised. For example, low-latency private APIs from exchanges like Coinbase and Kraken can significantly reduce this latency.

t2: Market Snap and Price Computation
Market Snap and Price Computation Latency is the time required for an oracle to aggregate and compute data from multiple liquidity venues. This process involves capturing real-time data from order books and trades, which are computed to provide an accurate market price snapshot. The more data sources and order book levels processed, the higher the latency.
To reduce this latency, providers can optimise by capturing data from fewer high-volume venues and improving their algorithms to handle larger datasets more efficiently. Typically, a minimum of three exchanges and ten order book levels are processed to balance accuracy and speed. Data from platforms like Uniswap can also be captured quickly to keep computation times low.

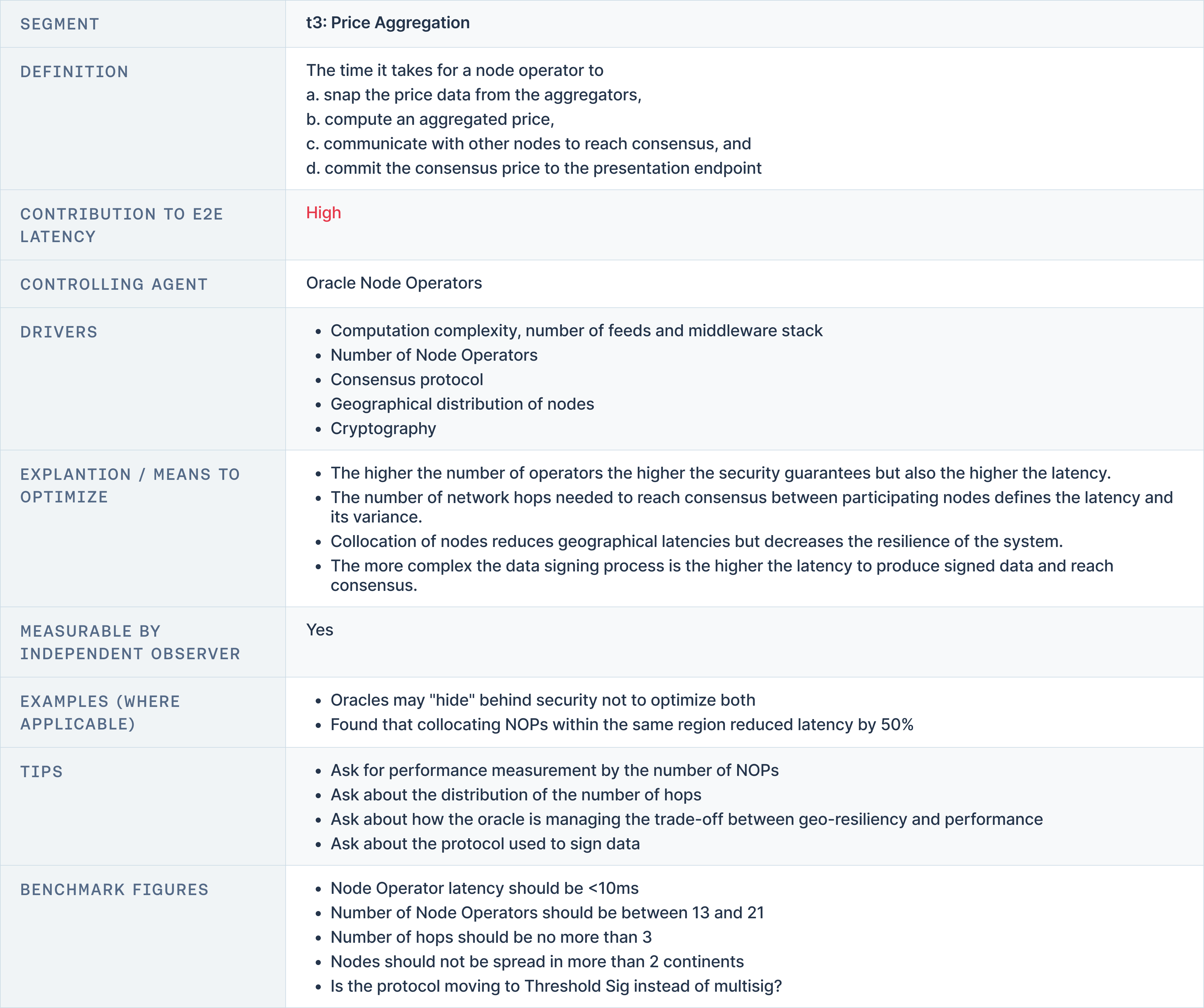
t3: Price Aggregation
Price Aggregation Latency is one of the more significant contributors to total latency. It represents the time required to synthesise data from multiple feeds or nodes, particularly in decentralised oracle networks. High aggregation latency can result from computational complexity, the number of data streams being processed, and inefficiencies in the underlying infrastructure.
Oracle systems reduce this latency by optimising node architectures and limiting the number of feeds when feasible. Utilising fast database solutions like Postgres also helps reduce data retrieval times. Oracle providers aim to keep node operator latency below 10 milliseconds to ensure price updates are delivered quickly across the network.
t4: Price Presentation
Price Presentation Latency represents the time it takes to display processed price data to the end user. This latency is influenced by the Oracle provider's internal middleware and queue management systems. Inefficiencies in this process introduce latency as data is prepared for end-user consumption.
To optimise this stage, providers use efficient queue management strategies and in-memory caching solutions like Redis, which speed up data retrieval. Providers aim to keep latency to the presentation server under 10 milliseconds, ensuring that data reaches the end-user promptly.

t5: Price Consumption
Price Consumption Latency is the final stage, where the end-user or application consumes the processed and presented data. The efficiency of this stage largely depends on how quickly the application can process and act upon the data. While this latency is generally low, inefficiencies in the consumption pathway can cause delays.
Oracle providers work with end-users to ensure real-time data feeds are supported and processed quickly. For high-performance applications like trading algorithms, consumption latency is typically kept below 50 milliseconds to ensure fast, actionable data delivery.

Measuring Latency
In the context of oracles, Latency refers to the time delay between the moment data is captured from the source and when it is made available to the end user.
The most effective way to measure latency is to track the end-to-end delay between data capture and data availability for consumption. This can be broken down into several steps:
- Time-stamping Data Capture: Record the exact moment the data is retrieved from the source, such as a liquidity venue or exchange.
- Time-stamping Data Presentation: Capture the time at which the data becomes available to the user or application, whether through an API call or another delivery method.
- Calculating Latency: Subtract the initial capture timestamp from the presentation timestamp. This value represents the total latency, typically measured in milliseconds (ms).
By measuring this over multiple data points, Oracle providers can compute an average latency and analyse how well the system performs under different conditions. For more granular insights, it is important to examine latency variation—how much the latency fluctuates depending on market volatility or load on the system.
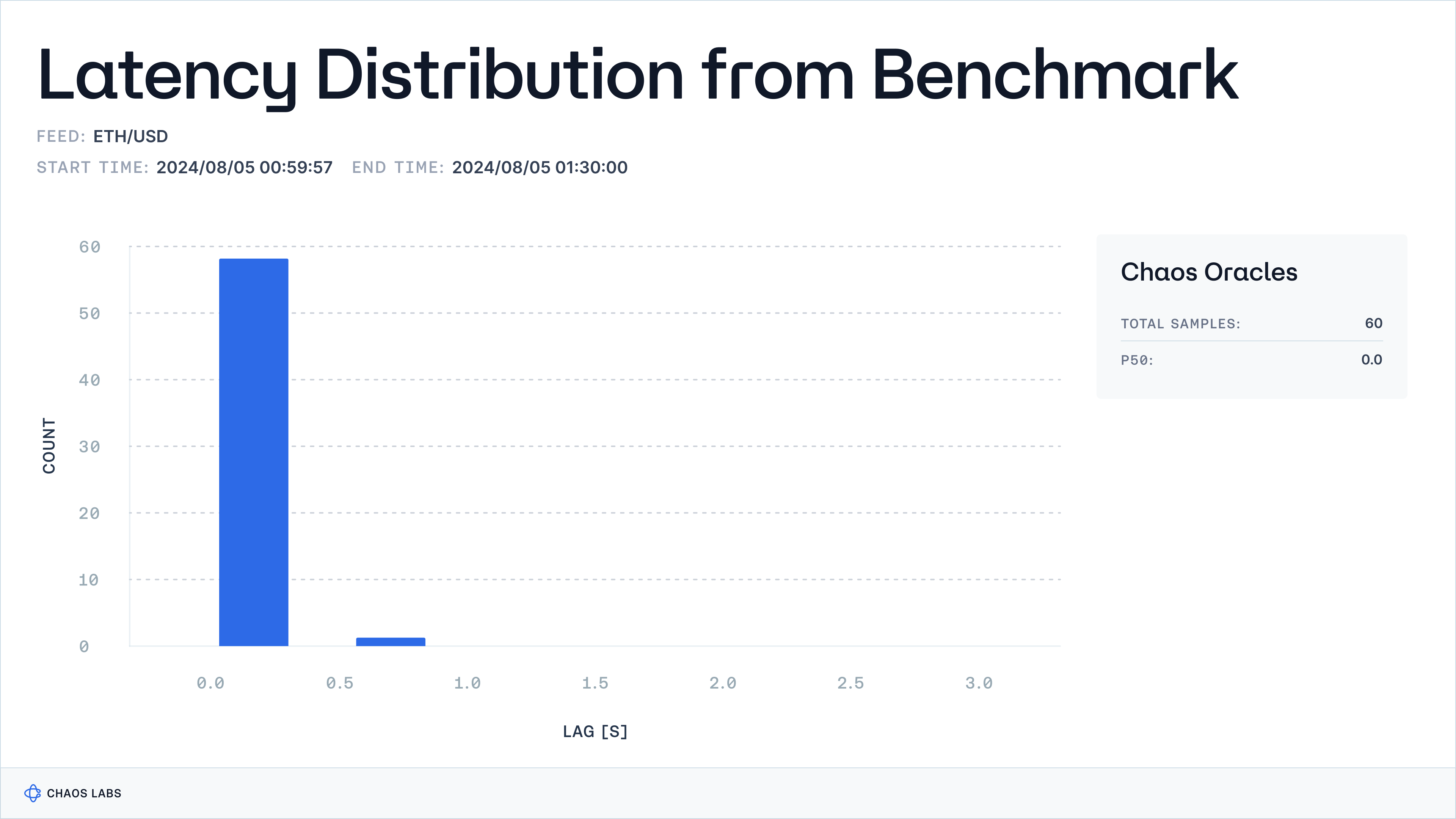
This chart shows the distribution of lags in price presentation for Edge, measured against data captured from Binance, the selected benchmark exchange. This is useful to assess how quickly Edge reflects price changes. This analysis illustrates Edge's efficiency, with consistently short lags, ensuring more immediate and up-to-date price data.
Strategies to Minimise Latency
Minimising latency involves optimising each component:
- t1: Enhancing data transmission speeds.
- t2: Optimising data processing algorithms.
- t3: Efficiently aggregating and verifying data across nodes.
- t4: Utilising fast data caching and retrieval systems for presentation.
- t5: Ensuring quick delivery mechanisms to end-users.
t1: Enhancing Data Transmission Speeds
- Rationale: The time taken to transmit data between liquidity venues and exchanges to oracles (t1) can introduce delays that affect the data's freshness. Minimising this transport latency is critical for timely decision-making.
- Implementation: Utilise low-latency networks, ideally with data capture close to key liquidity venues. This reduces the physical and network distance data must travel, thus speeding up transmission times. Additionally, minimising the number of network hops can significantly reduce latency.
- Optimisation Tip: Choose exchanges with APIs that support low-latency communication protocols, such as WebSocket over REST.
t2: Optimising Data Processing Algorithms
- Rationale: Efficient data processing ensures that the market data being snapped and computed is made available without significant delays. The time it takes for a price aggregator to process data from multiple sources (t2) impacts overall latency.
- Implementation: Employ high-performance algorithms capable of quickly processing large data sets, such as full order books. Running these algorithms on powerful hardware and using parallel processing where appropriate can also help reduce computation time.
- Optimisation Tip: Utilise real-time data streams instead of batch processing, and regularly audit your data-processing algorithms to ensure they’re optimised for speed and scalability.
t3: Efficient Data Aggregation and Verification
- Rationale: Aggregating and verifying data from multiple sources across nodes (t3) can become a bottleneck if not handled efficiently. Delays in this process can slow down the availability of accurate price data.
- Implementation: Streamline aggregation algorithms by limiting the number of exchanges used or prioritising data from the most liquid venues. Fast aggregation systems that can handle and mix multiple feeds effectively will further reduce latency.
- Optimisation Tip: Regular node optimisation, including the underlying database (e.g., Postgres), is crucial for fast execution.
t4: Utilising Fast Data Caching and Retrieval Systems
- Rationale: After data is processed and aggregated, the time it takes to retrieve and present it (t4) can impact the user experience. Fast caching systems reduce the need to query databases directly for every request, which speeds up data delivery.
- Implementation: Implement in-memory caching solutions like Redis to store frequently requested data. This reduces the time spent on repetitive queries and ensures that data is delivered to users as quickly as possible.
- Optimisation Tip: Optimise queue management systems to handle both incoming data and outgoing requests with minimal delays. This ensures the data flows smoothly from input to presentation without unnecessary slowdowns.
t5: Ensuring Quick Delivery Mechanisms to End-Users
- Rationale: The final component of latency involves delivering the processed and verified data to the end-user (t5). Delays in this step can negate the benefits of optimisations made in earlier stages.
- Implementation: Use content delivery networks (CDNs) to ensure rapid data distribution to end-users, regardless of their geographical location. Optimising the user interface for faster rendering of the presented data can improve the overall experience.
- Optimisation Tip: Minimise the size of the data packets delivered and use efficient transport protocols like UDP or gRPC for time-sensitive data.
Balancing Freshness, Accuracy and Latency
The Oracle Trilemma: Freshness, Accuracy, and Latency
In the context of oracle systems, freshness, accuracy, and latency are interconnected and can sometimes be at odds.
Achieving the ideal balance often requires trade-offs based on the specific application or market scenario. Here’s how each component interacts with the others:
1. Freshness vs. Accuracy
- Trade-off: Prioritising data freshness (i.e., update frequency) can sometimes come at the expense of accuracy. In fast-moving markets, it may be necessary to prioritise speed over detail to ensure that decisions are made based on the most current data. This can mean using rougher or less complete data snapshots that sacrifice granularity.
- Example: In high-frequency trading, where milliseconds can determine profitability, oracles often prioritise data freshness to align with market volatility. The data might not be perfectly precise, but its up-to-date nature is more valuable for immediate trading decisions.
2. Latency vs. Freshness
- Trade-off: Minimising latency (i.e., timeliness) is essential for ensuring fresh data reaches the end-user quickly. However, reducing latency might limit the scope for comprehensive data validation or aggregation, which can impact the accuracy of the delivered data.
- Example: For dapps, latency can influence the timeliness of price feeds used for liquidations or lending. Lowering latency may involve sacrificing additional checks or deeper data analysis to ensure faster delivery.
3. Accuracy vs. Latency
- Trade-off: Achieving high accuracy often requires more intensive data processing, which increases computation time and can add to overall latency. To guarantee precise data, especially in complex markets, data may need to be pulled from a broader range of sources or processed using sophisticated algorithms, all of which take time.
- Example: In contexts like trade settlement or risk management, where accurate price data is crucial, oracle providers might tolerate higher latency to ensure the final price data is as precise and detailed as possible.
4. Use Case-Dependent Prioritisation
- High-Frequency Trading: Freshness and low latency are critical. Traders prioritise receiving real-time, albeit slightly imprecise, data to make split-second decisions.
- Settlement Processes: Precision is paramount. Traders or platforms can afford a slightly higher latency if the data is exact for finalising financial transactions.
- Risk Assessment or Analytics: Data precision might be favoured, with some tolerance for latency, especially when decisions are not made in real-time but rely on historical accuracy and completeness.
Strategic Decisions in Oracle Architecture
Oracle providers must make deliberate architectural choices based on their end-use applications to optimise the balance between these three metrics.
Here are key decisions that impact performance:
1. Modular Design for Flexibility
- Rationale: Oracle systems can be built with modular components that allow specific use cases to prioritise freshness, accuracy, or latency independently. For instance, high-frequency applications can tap into low-latency data streams, while settlement systems can focus on aggregated, highly precise data.
- Implementation: Oracle architectures can include different data pipelines tailored to specific user needs, where some pipelines are optimised for speed (with lower precision), and others are optimised for accuracy (with greater latency).
2. Tiered Data Feeds
- Rationale: Implementing tiered data feeds allows oracles to offer multiple levels of data depending on the user’s requirements. Basic, low-latency data can be provided for real-time decision-making, while more refined, precise data can be available for later review or high-stakes applications like settlement.
- Implementation: By offering multiple “tiers” of data precision, an Oracle system can ensure that real-time feeds prioritise freshness, while historical or aggregated data sources provide more detail for applications prioritising accuracy over speed.
3. Use of Edge Computing
- Rationale: Placing computational resources closer to the data sources (e.g., through edge computing) can reduce the need for data to travel long distances, thus reducing latency and improving freshness without significantly compromising precision.
- Implementation: Oracles can speed up data capture and transmission by processing data closer to the liquidity venues or exchanges, enabling lower-latency feeds. This architecture reduces the physical delays in transporting data over long distances while allowing for processing and validation.
4. Adaptive Data Processing
- Rationale: Implementing dynamic systems that adapt to current market conditions allows for more flexible decision-making.
- Implementation: An adaptive architecture could automatically adjust its processing logic based on pre-defined market triggers, allowing real-time responses to changing conditions. For example, during low volatility, the system might emphasise precision and slower update intervals, whereas during market turbulence, it prioritises speed and freshness.
5. Advanced Anomaly Detection and Filtering
- Rationale: Anomalies or inaccuracies in data can lead to erroneous decisions, especially in high-stakes markets. To strike a balance, oracles can implement sophisticated anomaly detection systems to flag potential inaccuracies in real-time without introducing significant delays.
- Implementation: Oracle systems could integrate machine learning models that detect and flag outliers during data processing, allowing for rapid correction without halting the flow of data. This allows the system to maintain high precision while keeping latency low by handling errors swiftly.
Balancing freshness, accuracy, and latency requires making targeted, context-aware decisions in Oracle design. Understanding the trade-offs and leveraging architectural flexibility ensures the system remains efficient and robust across various use cases, whether for real-time trading, settlement, or risk assessment.
Conclusion
Chapter 5 systematically explores the pivotal roles of data freshness, precision, and latency in Oracle performance. These factors are not just technical specifications but are critical components that can significantly influence the trust and efficiency of Oracle services. By implementing rigorous standards and continuous monitoring of these aspects, Oracle providers can ensure that they deliver data that is not only timely and accurate but also secure. As the digital asset and blockchain landscapes evolve, the principles discussed herein will remain integral to developing robust and reliable Oracle services, ensuring they are equipped to handle the complexities of modern financial systems.
Chaos Proofs Oracles: AI-Powered Prediction Market Oracles
Chaos Proofs Oracles ensure verifiable data provenance, integrity, and authenticity, enabling blockchain applications to trust the external data they rely on. This capability is crucial for Prediction Market Oracles, a specialized subset of proof oracles designed to bring off-chain data on-chain in a secure and trusted manner, ensuring accurate verification of real-world outcomes like elections.
Introducing Chaos Oracles: The Next Generation Oracle Protocol
At Chaos Labs, we've always believed that robust risk management and reliable data are the foundations of a thriving DeFi ecosystem. With Edge, we're putting that belief into action, providing a solution that doesn't just report prices but actively contributes to the security and efficiency of on-chain finance.
Risk Less.
Know More.
Get updates on our research, product, and launch.