Oracle Risk and Security Standards: Network Architectures and Topologies (Pt. 2)
Introduction
Reference chapters:
- Oracle Risk and Security Standards: An Introduction (Pt. 1)
- Oracle Risk and Security Standards: Network Architectures and Topologies (Pt. 2)
- Oracle Risk and Security Standards: Price Composition Methodologies (Pt. 3)
- Oracle Risk and Security Standards: Price Replicability (Pt. 4)
- Oracle Risk and Security Standards: Data Freshness, Accuracy, and Latency (Pt. 5)
In our initial exploration of Oracle Risk and Security Standards, we reviewed the inherent limitations of blockchains, the pivotal role of oracles, and the fundamental challenges they address, underscoring their critical importance in the ecosystem. Additionally, we segmented the domain of Oracle Security into six distinct pillars set to be examined throughout this series.
Chapter 1 of the Oracle Risk and Security Framework introduces readers to the intricate world of Oracle Network Architecture and Topologies. This foundational chapter provides a detailed examination of how Oracle Networks are structured, data’s complex journey from source to application, and the inherent security and risk considerations within these systems. Through a deep dive into architectures, the data supply chain, and network topology, readers will understand the critical components that ensure the functionality and reliability of Oracles in DeFi, providing context for the challenges and innovative solutions that define the landscape.
Before diving into Oracle Network Architecture and Topologies, it's crucial to understand the underlying principle that shapes this landscape: the indispensable need for decentralization within Oracle Networks.
Why Do Oracle Networks Require Decentralization?
The 'Oracle Problem,’ outlined in the introductory chapter of this series, extends beyond the challenge of blockchains accessing external data; it includes ensuring the preservation of blockchain's core values:
- Censorship resistance
- Sybil resistance
- Redundancy
A centralized oracle compromises these benefits, threatening the principles that encourage on-chain development. To start, we will delve into specific examples of Oracle exploits that underscore the risks associated with centralized oracles.
In 2020, Compound Finance was subject to an Oracle exploit due to its dependency on Coinbase Pro’s API for the price of DAI. Unfortunately, the manipulation of the DAI/USDC market on Coinbase saw the price jump 30% to $1.30, leading to ~$90M of wrongful liquidations. This attack highlighted the issue of limited exchange coverage, allowing a malicious actor to trigger liquidations of users and yield farmers who had DAI as collateral or debt. A proposal for Compound to integrate Chainlink Price Feeds — which incorporate prices from numerous exchanges rather than just one or two — passed shortly after. This integration was intended to mitigate the risk of similar manipulative attacks in the future, ensuring a more secure and reliable platform for users.
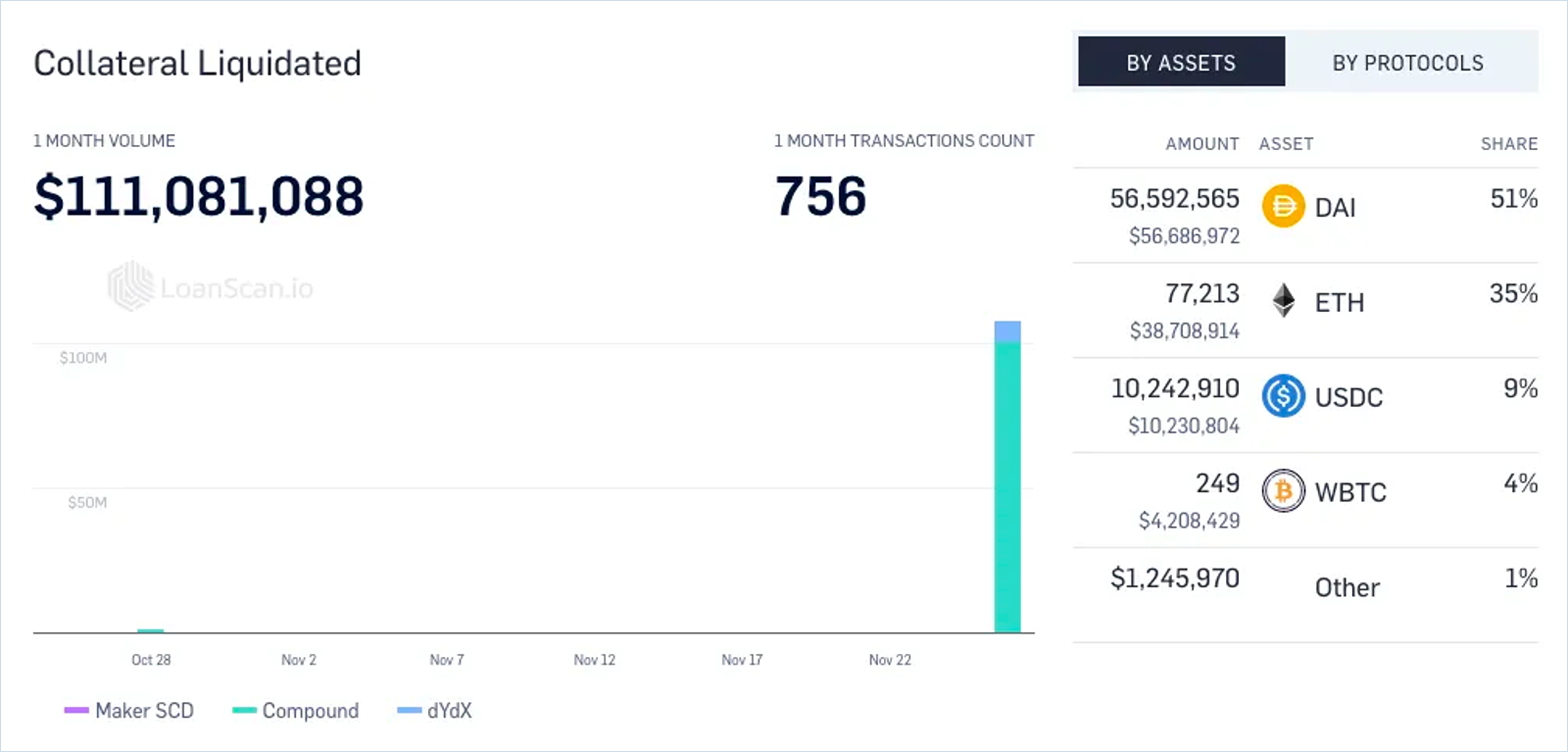
Only a year later, crypto data aggregator CoinMarketCap experienced a bug that incorrectly reported cryptocurrency prices despite exchange data remaining accurate. The error inflated Bitcoin's price to $789 billion and its market capitalization to $14.7 quintillion. DeFiChain, a Bitcoin-focused lending platform, was one of many protocols that announced the temporary suspension of its services to ensure the protection of user funds.
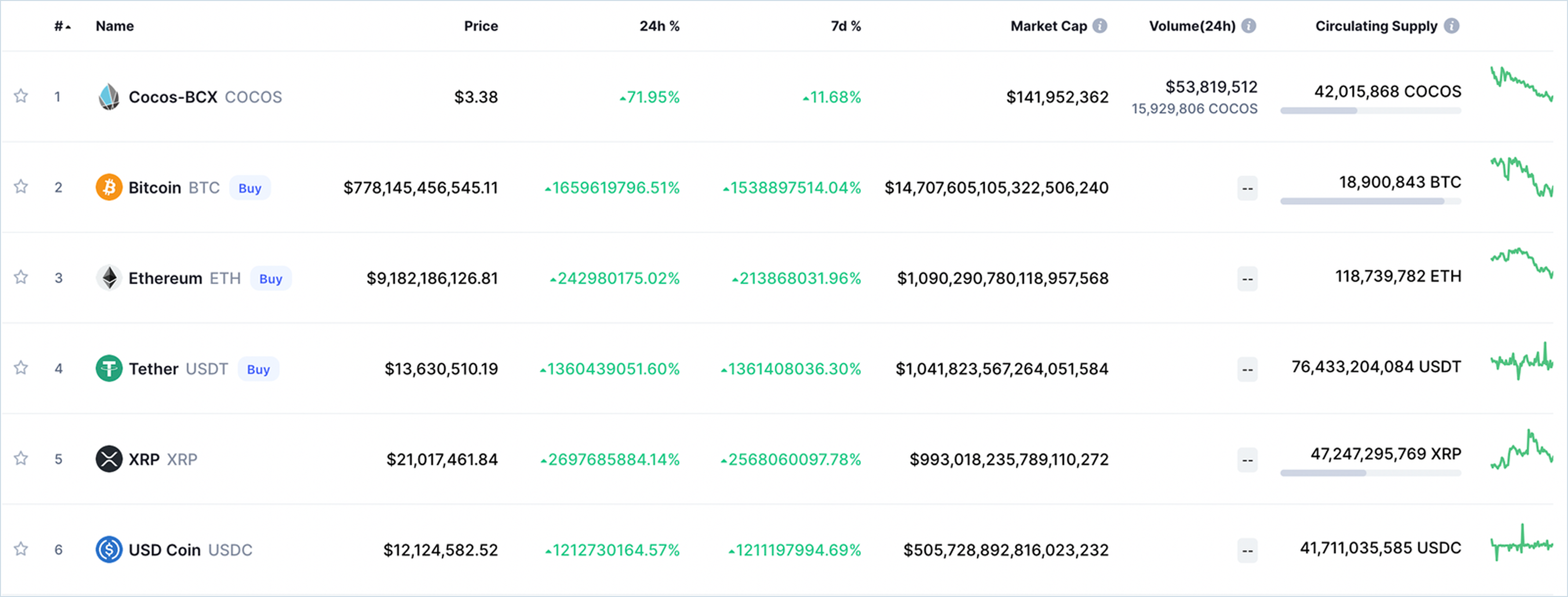
These expensive failure cases, such as the Coinbase API manipulation and CoinMarketCap’s misreporting, highlight that a more robust, decentralized Oracle architecture is needed to combat vulnerabilities, from malicious exploits to technological failures.
Risks of a Centralized Price Oracle System
Centralized Data Sourcing
As illustrated in the case of Compound and DeFiChain, an Oracle system that relies on a single source for price discovery exposes systems to significant centralization risks. This setup not only jeopardizes reliability due to a lack of redundancy—increasing vulnerability to failures or manipulations—but can also compromise the breadth of market coverage. A singular source may fail to capture a comprehensive view of the market, leading to inaccuracies in reported data.
Centralized Validation
Oracle systems that concentrate decision-making and data processing in a single entity introduce a vulnerability through which a compromise or failure of that entity can disrupt the entire Oracle’s functionality. Even if a network of oracles exists, if a single entity operates the validator nodes, it can arbitrarily alter reported data. This presents a unique attack vector: if hackers gain control over these nodes, they can manipulate data to their advantage, exposing dependent systems to skewed or fraudulent information.
Limited Transparency
Centralized systems often operate as black boxes, offering limited visibility into their data sourcing and processing methods. This opacity compromises verifiability, a core principle of blockchain technology that enables the verification of every transaction. Similarly, for oracles, users should be able to trace the data path from the on-chain report back to the oracle node's query of the data source, ideally supported by some form of cryptographic signature related to that query or aggregated data point. The lack of transparency in how data is sourced and processed can erode trust among users who depend on the integrity of this data for critical decision-making processes.
Challenges of Operating a Decentralized Price Oracle System
Despite the clear necessity for decentralization within Oracle networks, bootstrapping a robust decentralized system is fraught with technical challenges, particularly those related to network communication, which can significantly hinder performance and reliability.
Synchronizing Data Across Nodes
Ensuring consistent data across all participating nodes in a decentralized network poses a significant challenge, especially given the varying response times and potential data discrepancies that can arise from disparate sources.
Maintaining Data Integrity Amid Latency
High latency in network communication can delay the transmission of critical data updates, complicating the maintenance of data accuracy and timeliness crucial for timely decision-making in decentralized applications.
Achieving Consensus Under Adversarial Conditions
Establishing a reliable consensus mechanism that functions efficiently across a decentralized oracle network, especially under network congestion or targeted attacks, remains a complex undertaking.
Difficult Design Trade-Offs
Navigating the trade-offs between centralized and decentralized Oracle architectures reveals a balance between efficiency and security, highlighting the complexity of choosing the optimal framework for Oracle networks.
Thanks to their singular control points, centralized Oracle architectures offer streamlined decision-making and potentially faster data processing. However, this centralization poses significant risks, including vulnerability to manipulation, single points of failure, and compromised data integrity. In contrast, decentralized oracle networks enhance security and resist censorship or attacks through distributed control. Still, they face challenges related to consensus achievement, higher latency, and the complexity of maintaining data accuracy across numerous nodes.
Understanding these trade-offs prepares us to delve into the nuances of the CAP Theorem and the inherent challenges distributed systems face, further exploring the delicate equilibrium between consistency, availability, and partition tolerance in decentralized networks.
CAP Theorem
The CAP theorem is a principle in distributed computing that states that it is impossible for a distributed data system to guarantee all of the following three properties simultaneously:
- Consistency (C): Every read operation in the system returns the most recent write for that data item or an error.
- Availability (A): Every request made to the system receives a response, regardless of the current state of the system or any failed nodes.
- Partition Tolerance (P): The system continues to operate despite arbitrary message loss or network partitioning between nodes.
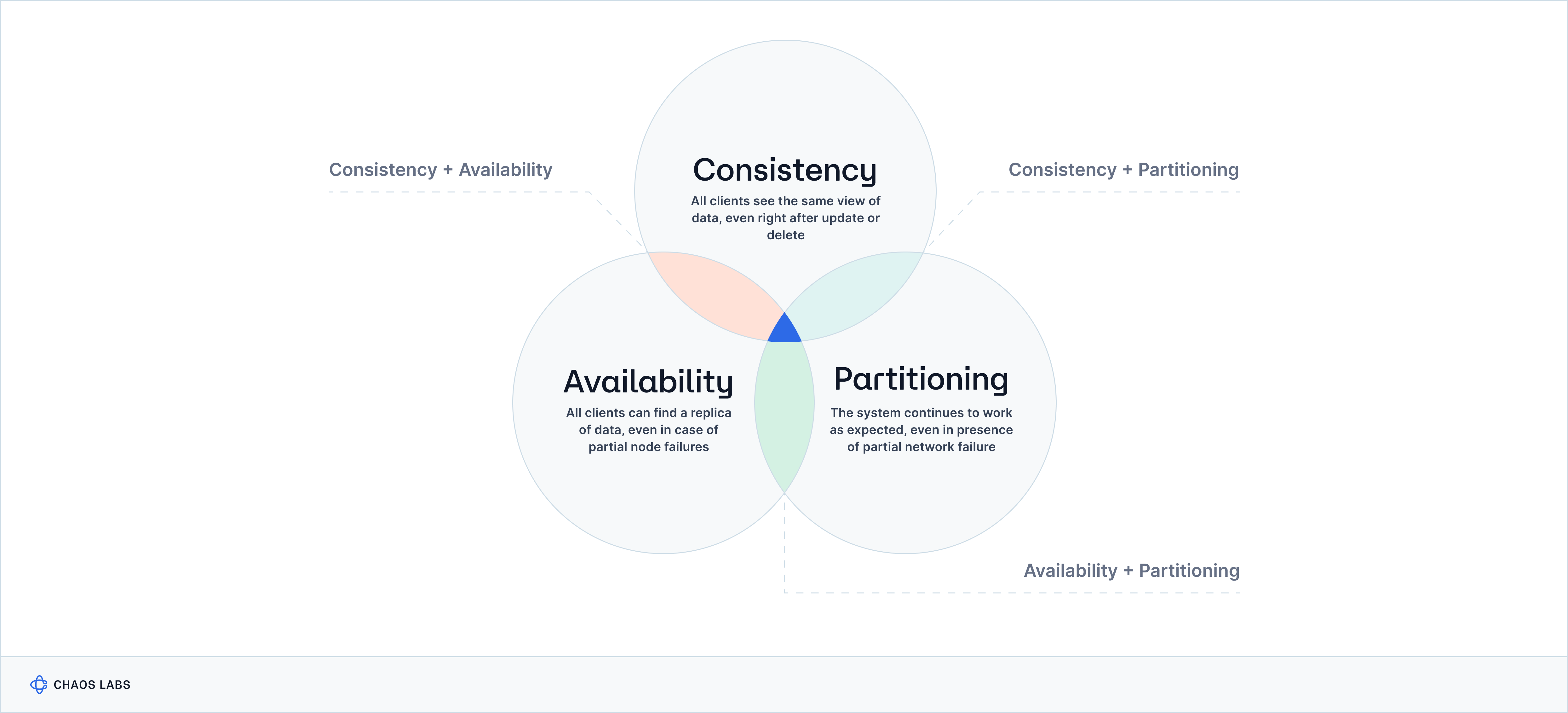
According to the CAP theorem, a distributed data system can only guarantee two properties simultaneously. This means that in the event of a network partition (P), the system must choose between sacrificing either consistency (C) or availability (A).
For example, in a network partition scenario where nodes cannot communicate with each other, the system can either maintain consistency by halting operations until the partition is resolved (CP) or prioritize availability by allowing nodes to continue operating independently but potentially sacrificing consistency (AP).
- Consistency (C): If the system prioritizes consistency (C), it ensures all users see the same data simultaneously. For example, when customers update their shopping cart, the system waits until the change is propagated to all database nodes before confirming the update. This guarantees that all subsequent reads of the shopping cart return the updated information. However, during network partitions or node failures, the system may become unavailable, leading to potential downtime or delayed responses until the partition is resolved.
- Availability (A): Alternatively, if the system prioritizes availability (A), it aims to always respond to user requests, even in the face of network partitions or node failures. For example, when customers update their shopping cart, the system immediately confirms the update. It allows the user to continue shopping, regardless of whether the change has been propagated to all nodes. This ensures uninterrupted service for users but may lead to temporary inconsistencies in data, such as different users seeing different product quantities due to eventual consistency mechanisms.
- Partition Tolerance (P): Regardless of the chosen trade-off between consistency and availability, the system must be partition-tolerant (P), meaning it can continue to operate despite network partitions or communication failures between nodes. In our example, even if some nodes are unreachable due to a network partition, the system should still be able to process user requests and maintain overall functionality.
The CAP theorem is a guideline for designing and understanding the trade-offs inherent in classic distributed systems, helping developers make informed decisions based on their applications' specific requirements and constraints. Let’s review this theorem through a tangible example.
CAP Theorem Example: Perpetuals Exchange
Imagine you have an on-chain Perpetuals exchange offering traders high levels of leverage. The exchange is integrated with a decentralized Oracle network for price discovery. Price data is critical to executing core platform functionalities, such as liquidations, which help the protocol manage risk and avoid a collateral shortfall. Should the decentralized Oracle network experience a partition wherein some Oracle nodes are still reporting prices while others are down, the exchange must select whether to prioritize price availability, which might risk the reporting of incorrect prices, potentially triggering unjust liquidations or exploitative trades, or optimize for price consistency, in which case the exchange may have to temporarily halt trading until the minimum quorum of oracles required for consensus is reached. Failing to attain price consistency exposes the exchange to the risk of incurring bad debt through missed liquidations. During elevated volatility, the severity of this risk is especially pronounced, highlighting the importance of both properties.
The CAP theorem forces system designers to make conscious trade-offs between consistency and availability based on their applications' specific requirements and constraints. While it may not be possible to achieve perfect consistency and availability simultaneously, understanding these trade-offs helps ensure that distributed systems are designed to meet the desired level of reliability and performance.
Ensuring Integrity in Adversarial Environments
Their operational environments shape the functionality of Oracle Networks and the imperative for trustlessness, necessitating Byzantine Fault Tolerance (BFT) to mitigate vulnerabilities like Sybil attacks. This leads us to explore the Byzantine Generals Problem, a foundational issue that underscores the need for robust consensus mechanisms in decentralized Oracle systems to maintain security and integrity in adversarial settings.
Byzantine Generals Problem
The Byzantine Generals Problem is a classic problem in computer science. It illustrates the challenges of achieving consensus in a distributed system where some participants may act maliciously or fail to communicate. The problem is named after an allegorical situation involving a group of generals who must agree on a joint battle plan, but where some generals may try to disrupt the consensus through lies or silence. Here's a clear explanation using the metaphor:
Imagine a group of Byzantine generals, each commanding a portion of the Byzantine army, encircling a city they intend to attack. The generals can only communicate with each other through messengers. The generals must agree on a shared action plan for the attack to succeed: either they attack or retreat. However, there are a few complications:
- Some generals may be traitors: Among the generals, some traitors seek to prevent the loyal generals from reaching a consensus. A traitor could send conflicting messages to different generals to create disagreement on whether to attack or retreat.
- Communication is unreliable: Messages between generals may be lost, intercepted, or altered, further complicating the ability to reach a consensus.
- All loyal generals must agree on the same plan: For the attack to be successful (or the retreat to be safe), all loyal generals must carry out the same action. Even one loyal general doing something different could lead to disaster.
The Byzantine Generals Problem asks: is it possible to design an algorithm that allows loyal generals to reliably agree on a plan despite traitors and the possibility of communication failures?
This problem is directly applicable to Oracle protocols, where nodes (representing the generals) must agree on a shared state or decision (the battle plan) despite the presence of malicious nodes (traitors) and unreliable communication. Solving this problem is crucial for Oracle networks, where achieving reliable consensus is essential for the system's integrity and trustworthiness.
Consensus algorithms that solve the Byzantine Generals Problem are considered Byzantine Fault Tolerant because they enable a system to reach an agreement on a single course of action or state of truth, even in the presence of malicious actors or faulty components.
These algorithms are adept at handling scenarios where participants may behave unpredictably, lie, or fail to communicate, ensuring the system can function correctly and reliably. By providing a mechanism for consensus despite these challenges, they uphold the integrity and reliability of decentralized networks, making them resilient to a wide range of potential faults and attacks. This capability is fundamental in maintaining the trust and security essential for operating decentralized systems.

Oracle networks must implement robust consensus mechanisms, cryptographic techniques, and redundancy measures to mitigate the risk of Byzantine faults and ensure data reliability. By prioritizing resilience and reliability, DeFi can build a foundation of trust and security, fostering the growth of a vibrant and sustainable ecosystem.
In summary, Byzantine Fault Tolerance is a fundamental requirement for Oracle networks and blockchain protocols because it upholds the systems' security, reliability, and adherence to the principles of decentralization and trustlessness in potentially adversarial environments. BFT mechanisms enable these networks to withstand technical failures, deliberate attacks, and malicious behaviors, safeguarding the network's functionality and value.
Properties of Distributed Oracle Systems
BFT with Designated Leader or Leader Election
Mechanism
In BFT systems that use a designated leader or leader election, consensus is typically achieved through a structured process. A leader is chosen randomly, through a deterministic process, or by election among the nodes. This leader is responsible for proposing the next block or set of transactions that should be added to the ledger. The other nodes in the network then validate this proposal and vote on its acceptance. If the leader becomes malicious or faulty, a new leader is elected to take over the process.
Efficiency
Having a designated leader can make the consensus process more efficient, as it centralizes the proposal mechanism, reducing the amount of communication needed to reach consensus compared to a system where all nodes communicate equally with each other.
Examples
Algorithms like Practical Byzantine Fault Tolerance (PBFT) and variations of it often employ a leader-based approach to efficiently manage the consensus process.
Vanilla Gossip Protocol
Mechanism
In a vanilla gossip protocol, information spreads through the network by nodes randomly communicating with other nodes. Each node shares and receives information with a subset of different nodes in an iterative process, eventually leading to the dissemination of information across the entire network. This method does not inherently include a mechanism for consensus or agreement on a single truth; it's primarily a way to distribute information.
Efficiency
While gossip protocols are highly resilient and ensure that information eventually reaches all parts of the network, they may not be as efficient in reaching consensus because of the extensive communication required. The lack of a central authority or designated leader in a pure gossip system can lead to higher communication overhead and slower convergence on consensus.
Use Cases
Gossip protocols are often used for information dissemination and membership management in distributed systems but might be adapted with additional mechanisms for consensus purposes.
Categorization and Differences
The two approaches are categorized differently because they address the challenge of consensus and fault tolerance from distinct angles. BFT algorithms with a designated leader or leader election are designed to ensure reliability and agreement in the face of Byzantine faults, focusing on structured consensus mechanisms that efficiently handle malicious or faulty nodes. In contrast, vanilla gossip protocols are more about robust information dissemination across a network and may require additional structures or algorithms to achieve consensus.
While both approaches are used within distributed systems, they serve different purposes and operate based on other principles. BFT algorithms with leadership mechanisms are directly aimed at achieving consensus in a fault-tolerant manner, whereas gossip protocols excel at distributing information and require modifications to function as consensus mechanisms in Byzantine environments.
Overview of Oracle Architectures
Building on the foundational understanding of the CAP Theorem and the intricacies of oracle consensus mechanisms, our exploration transitions into the domain of oracle architectures. We dissect three prominent Oracle architectures:
- Decentralized Oracle Networks
- Oracle Blockchains
- Enshrined Oracles
Each is poised uniquely within the Oracle landscape to navigate the challenges distributed systems pose. As we delve into these architectures, our focus sharpens on the distinct risk and security vectors they embody, informed by our prior discussions on the importance of Byzantine resilience and the critical role oracles play in the DeFi landscape. This segment aims to unravel the technical underpinnings and security considerations shaping Oracle technologies, which are crucial for advancing robust and reliable DeFi applications.
Decentralized Oracle Networks (DONs)
A Decentralized Oracle Network (DON) is a framework designed to aggregate and validate external data through a network of independent nodes, or ‘Oracles.’ This consists of a peer-to-peer network that runs a consensus protocol to ensure a quorum of oracles can communicate and agree on the validity of the aggregate price report. Each consensus round culminates in producing an aggregate price report cryptographically signed by the oracles. Unlike a blockchain, a DON is stateless, which means that the DON does not store historical price reports. Instead, price reports are transmitted to a blockchain or cached off-chain for additional computation.
There are two primary approaches to DON architectures: the monolithic model utilizing a single network and the modular strategy employing multiple networks. Below, we shall explore these designs in the context of Chronicle (monolithic) and Chainlink (modular).
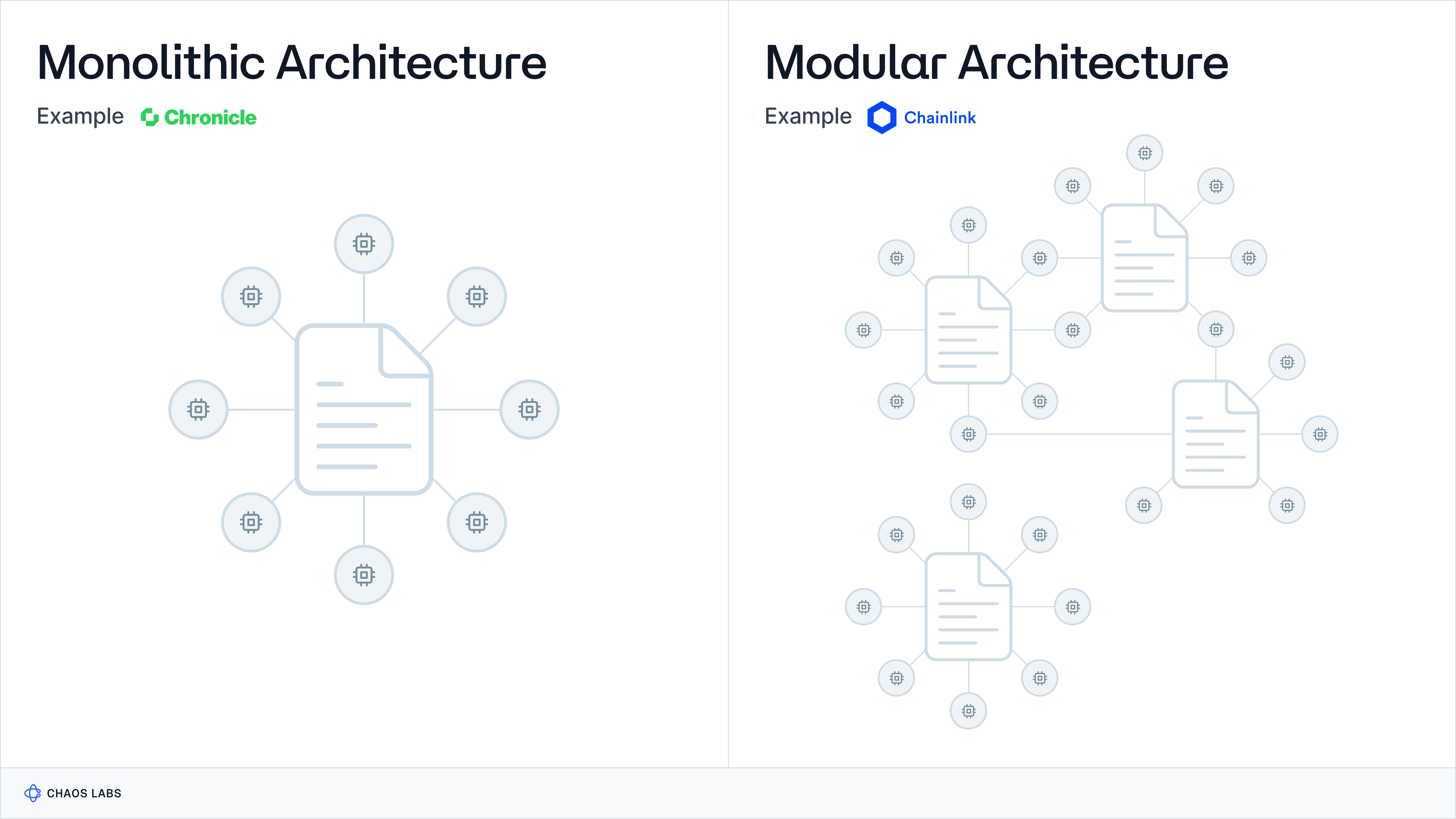
Case Study: Chainlink
Chainlink is an early pioneer of the DON model and a key proponent of its application in the Oracle space. Its innovation lies in the adoption of its Off-Chain Reporting (OCR) Protocol, a lightweight Byzantine consensus protocol that ensures the secure and efficient production of price reports off-chain. The Oracle node operators participating in each DON are transparently shown on the data.chain.link for each feed; however, the third-party data providers each node operator is streaming from remain opaque.
Chainlink's architecture involves multiple independent Oracle Networks operating together to provide secure and reliable data to smart contracts. This multi-network architecture enhances overall system reliability, as network downtime can be contained to a single DON. The architecture's heterogeneous nature ensures it can adapt to various feed types, servicing a broad range of blockchains. While the scope of this Oracle Standards series is explicitly focused on price oracles, this architecture also supports a more diverse range of Oracle services, such as cross-chain communication, smart contract automation, and generating on-chain verifiable randomness.
Data Aggregation and Dissemination
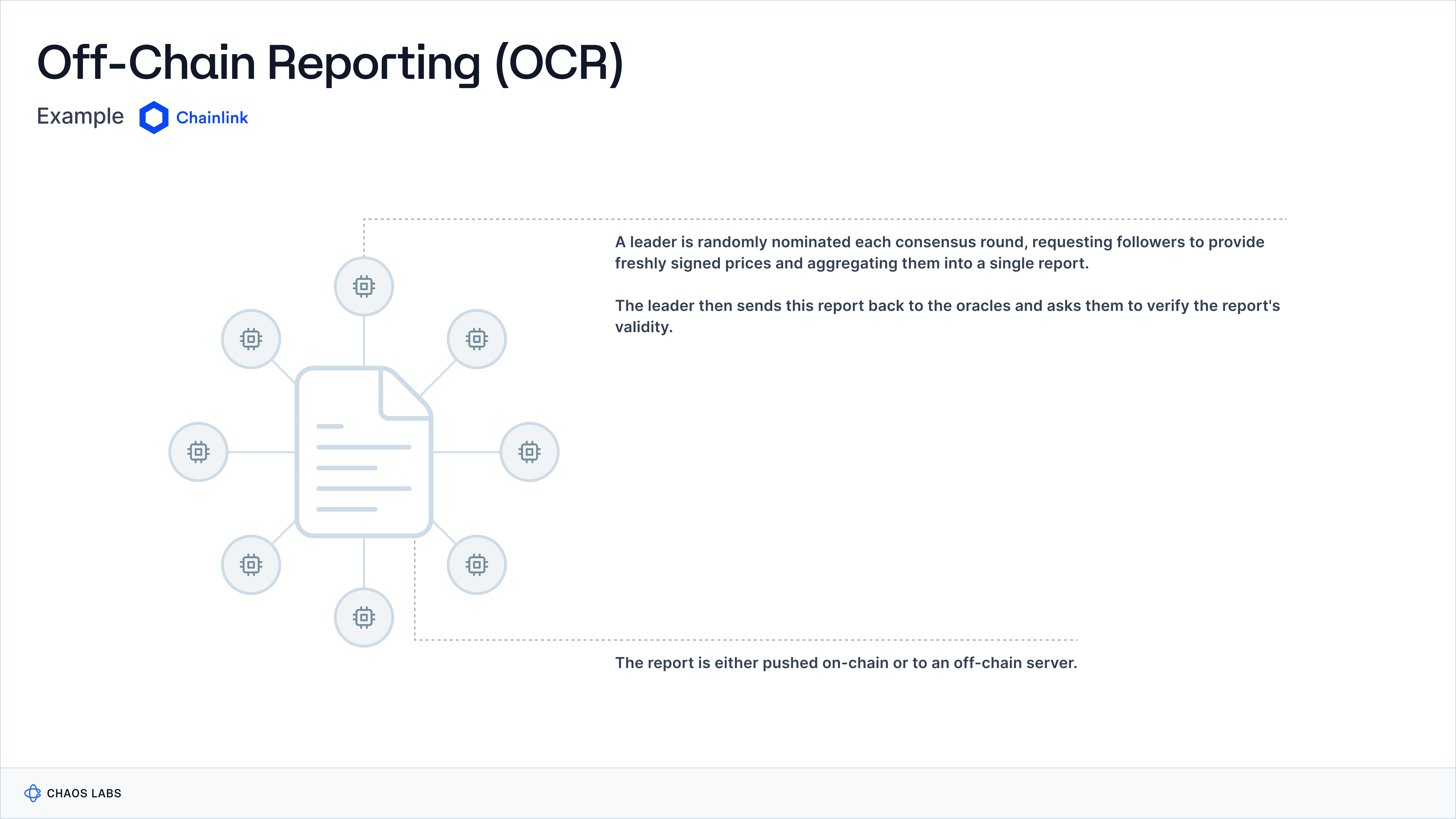
Chainlink OCR is a protocol that enables multiple Oracle nodes to securely and efficiently aggregate data, reaching consensus off-chain. The protocol can be divided into three parts:
- Pacemaker: governs the start and end of each epoch
- Report Generation: gathers oracle observations and generates a report once a quorum of oracles has submitted signed observations
- Transmission: disseminates the aggregate report to the destination
Each epoch, a randomly elected leader solicits freshly signed observations from all participating oracles and combines them into a single report. The leader circulates this report back to the oracles for confirmation of its validity. Once the minimum threshold of oracles returns a signed acknowledgment to the leader, a final report with the quorum's signatures is broadcast across the network.
Security and Fault Tolerance
Chainlink OCR’s security model allows less than a third of the oracles in a network to exhibit Byzantine faults—meaning they can act unpredictably or as though compromised—while still maintaining protocol integrity, provided the remaining oracles operate honestly. This framework assumes optimal operation with a configuration of n = 3f + 1 oracles to achieve maximal resilience against such faults, including network failures or crashes.
OCR maintains high reliability and accuracy by requiring a minimum quorum of two-thirds of nodes for data consensus and allowing for up to one-third of nodes to be Byzantine without compromising network integrity. This careful balance between quorum size and fault tolerance thresholds ensures that Chainlink's DONs remain secure and operational, even in adversarial conditions, by safeguarding against the influence of compromised nodes on the network's consensus process. Additionally, the model accommodates benign faults, where a temporarily non-responsive or unreachable node can recover and resume correct protocol participation, ensuring the protocol's safety isn’t compromised.
Case Study: Chronicle
Chronicle Protocol, formerly the Oracle Core Unit at MakerDAO, is renowned for deploying Ethereum’s first on-chain Oracle in 2017. Chronicle’s core innovation is its Schnorr multi-signature aggregation scheme, which significantly enhances the efficiency and scalability of validating multiple parties with a single aggregated signature. Using Schnorr signatures, a less common but highly secure alternative to ECDSA, ensures non-malleability and tampering resistance, crucial features for maintaining oracle integrity.
Data Aggregation and Dissemination
Chronicle uses different terminology to refer to the nodes submitting signed price observations, labeling them validators. Further, Chronicle’s terminology Decentralised Validator Network (DVN) leverages Schnorr signatures to streamline the validation process across its network, ensuring that multiple validators can confirm data at a constant rate.
Furthermore, the Optimistic Scribe architecture introduces an innovative, scalable solution for data verification on Ethereum. It maintains protocol integrity by ensuring that only validated and honest data updates are accepted.
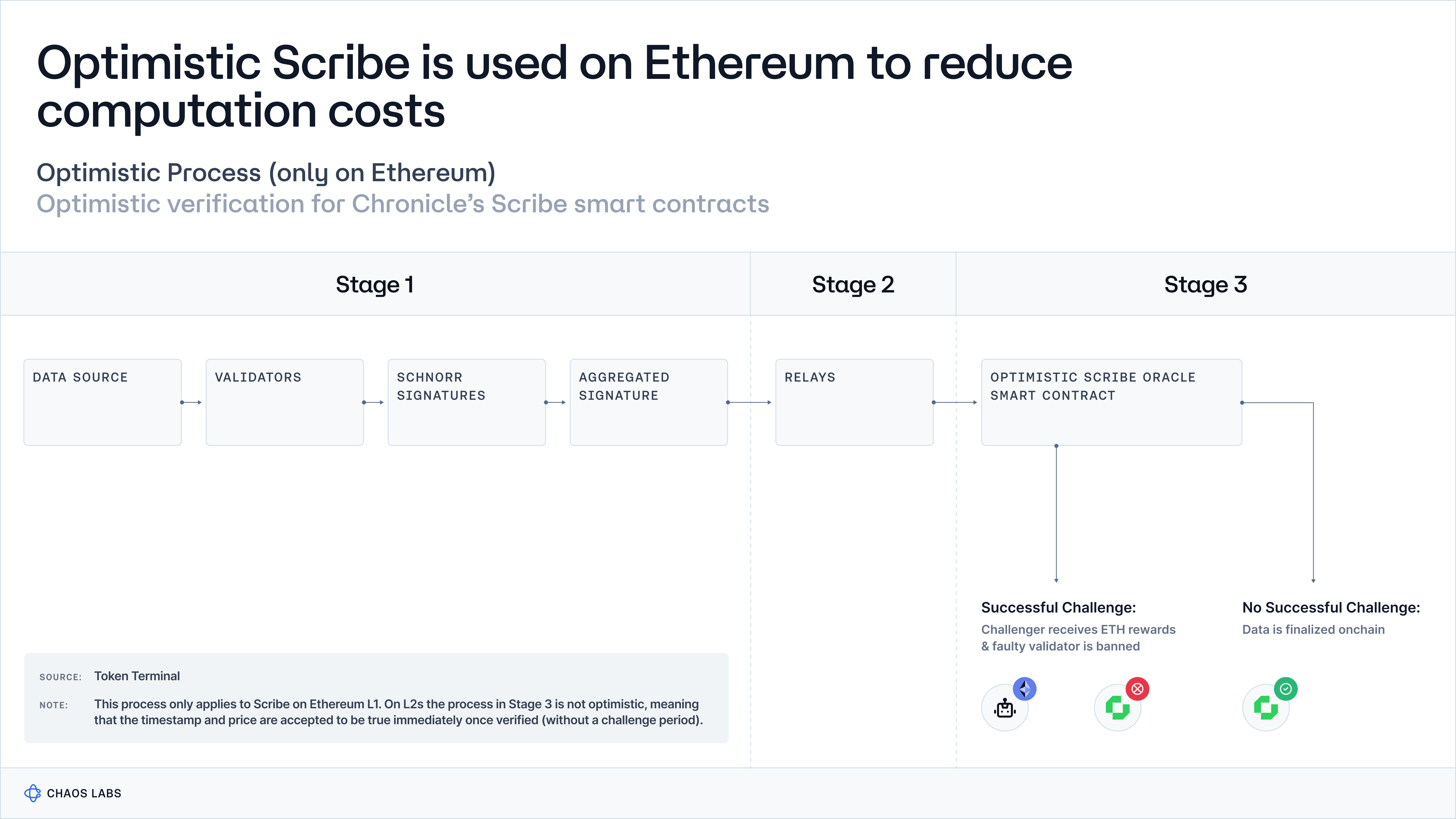
Security and Fault Tolerance
The Chronicle Protocol's security and fault tolerance hinge on the premise that no more than 50% of its validators act maliciously. This ensures operational integrity through a required quorum of honest validators for consensus. This foundational trust is bolstered by comprehensive security measures and a diversified validator pool to prevent malicious actors from dominating and enhance network resilience.
Oracle Chains
Oracle blockchains represent a monolithic approach to integrating exogenous data with blockchain systems, directly embedding data verification and storage within a single, unified network. This section explores how these application-specific blockchains work, detailing the processes of data aggregation, dissemination, and managing security and fault tolerance. As we delve deeper into these concepts, Pythnet will serve as a prime example, showcasing the practical application of an Oracle blockchain in action.
Case Study: Pythnet
Pythnet is a permissioned proof-of-authority appchain built on the Solana Virtual Machine (SVM), designed to aggregate data from Pyth’s network of publishers and produce a fresh price every slot (~400ms). The SVM’s adoption of predeclared dependencies and pipelining enables Pythnet to realize a high transaction throughput and, in turn, price update frequency.
On Pythnet, data providers submit prices and validate the network, reducing the latency between price source and aggregation in the Oracle program. Pyth’s core innovations are its emphasis on sourcing from first-party data publishers, such as exchanges and trading firms, and its pioneering of the pull-based oracle consumption model, since adopted by Chainlink, Stork, and RedStone.
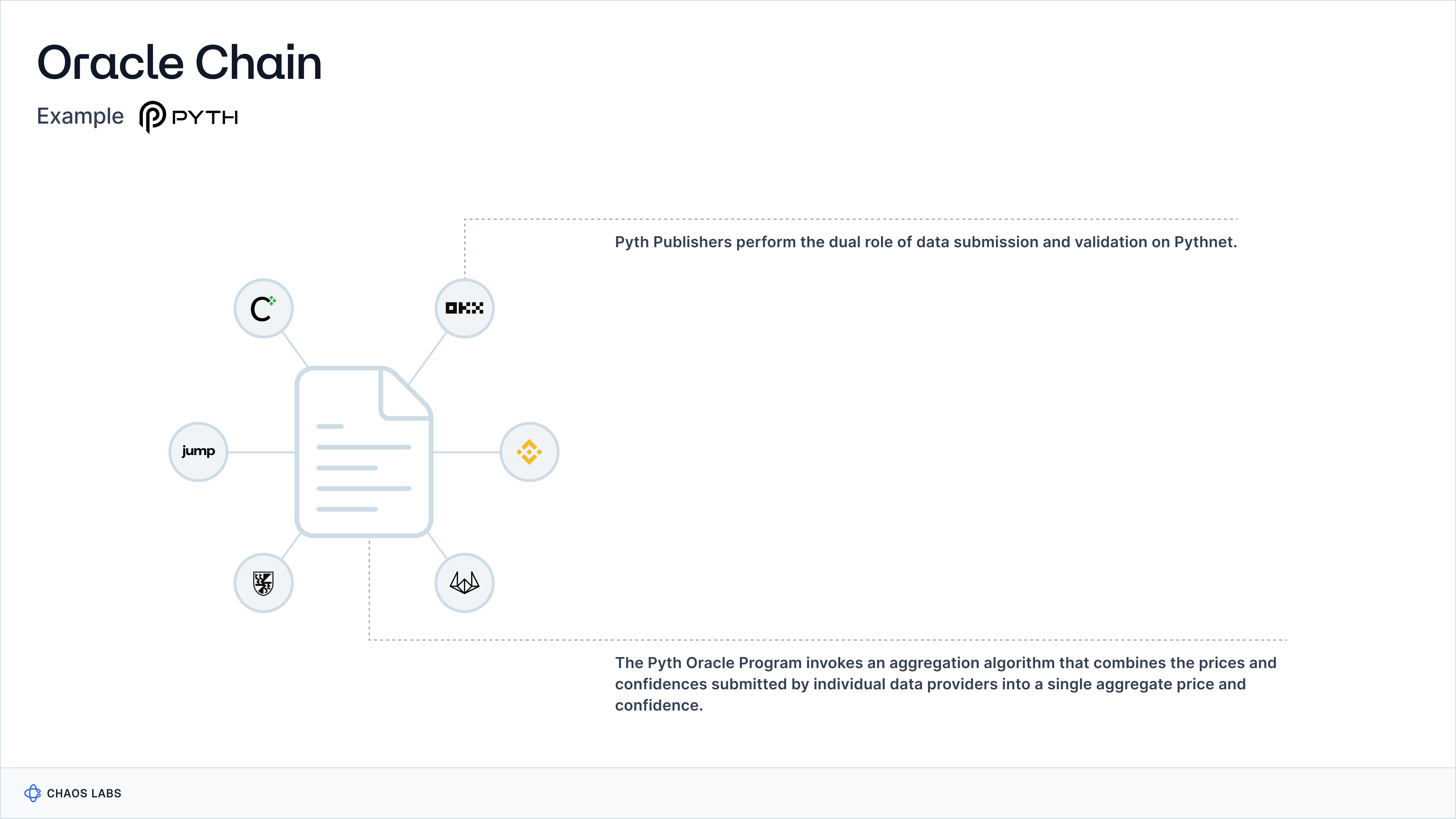
Data Aggregation and Dissemination
On Pythnet, price data is aggregated from “first-party” data providers. First-party data providers participate directly in price discovery, whereas third-party data providers aggregate price data from multiple venues. However, in the case of Pyth, the distinction between the two can be somewhat blurry; data providers like Kaiko and Amberdata — who aggregate from multiple venues — are referred to as first-party providers. The prices submitted by data providers are aggregated via an Oracle Program on Pythnet into a single composite price and then stored locally in a price account.
The Pyth Oracle Program employs a sophisticated aggregation algorithm responsible for compiling data from publishers to generate an aggregated price and confidence interval for each price feed. The aggregation process itself involves two steps. First, it computes the aggregate price by giving each publisher three votes — one at their reported price and one at the bounds of their confidence interval — and then selects the median of these votes. Second, it establishes the aggregate confidence interval by determining the distance from the aggregate price to the 25th and 75th percentiles of all votes, choosing the more significant distance as the confidence interval's range. This methodology effectively balances between the mean and median, allowing publishers with higher confidence (tighter intervals) more influence while limiting the impact of any single outlier.
Data is submitted to Pythnet, aggregated by the Oracle Program, and then distributed to other blockchains through Wormhole's cross-chain messaging protocol. Pyth employs a message buffer system and Merkle tree hashing to optimize efficiency and cost before routing data through Wormhole. This process allows for selective transaction updates and cost-effective data dissemination. Pythnet validators are crucial in creating a Merkle tree for every update, which Wormhole Guardians then authenticate. These guardians generate a Verifiable Action Approval (VAA), ensuring the data's reliability and security as it moves between blockchains, with signatures from Wormhole Guardians confirming the data's authenticity.

Security and Fault Tolerance
Pythnet's adoption of a Proof-of-Authority (PoA) consensus mechanism significantly enhances the appchain's security and fault tolerance. By designating a limited number of authorized validators, which are typically known and reputable entities, PoA ensures a high level of integrity and reliability in the network's operations. This curated approach minimizes the risk of malicious activities and ensures that only those with proven trustworthiness can validate transactions and updates. Furthermore, the PoA framework allows for swift consensus, reducing the possibility of network downtime and ensuring consistent availability. Pythnet's use of PoA consensus delivers a robust and resilient infrastructure ideal for supporting its specialized data aggregation and dissemination activities by optimizing the balance between security and operational efficiency.
Enshrined Oracles
Enshrined oracles are integrated within a blockchain's protocol, providing a built-in way to fetch and verify external data directly. Unlike DONs or Oracle Chains, they are an extension of the consuming blockchain’s infrastructure. This integration allows the blockchain to support complex operations and decisions based on accurate, timely data without external Oracle services. Slinky’s integration into the dYdX app chain is likely the most prominent example of an enshrined oracle.
Case Study: Slinky
In the context of Slinky integration with dYdX’s appchain, validators implement an oracle module that uses vote extensions (a term used on Cosmos to describe submitting additional data to a block) during the consensus process, which can include pricing data. Slinky integrates seamlessly into this architecture by acting as the enshrined oracle that supplies the pricing data through vote extensions, allowing validators on dYdX’s appchain to include this critical information directly in the block validation process, thereby enhancing the system's efficiency in updating state with precise and verified external data.

Data Aggregation and Dissemination
Slinky employs a sophisticated data aggregation and dissemination system, utilizing the Slinky Sidecar as an external service to efficiently gather prices from a network of data providers. This system processes and aggregates these prices into a consolidated price for each feed, which validators then fetch via GRPC requests. Slinky makes sure everything is safe and orderly by breaking down the process into steps using ABCI++. This includes checking the prices at the start, making sure they're valid, and then adding this information to the blockchain so that all validators can agree. To make any updates to the blockchain, at least 2/3 of these validators need to decide. This process happens with every new block, providing a steady flow of accurate prices. This method is crucial for keeping the blockchain running smoothly and ensuring the oracle's data is always reliable.
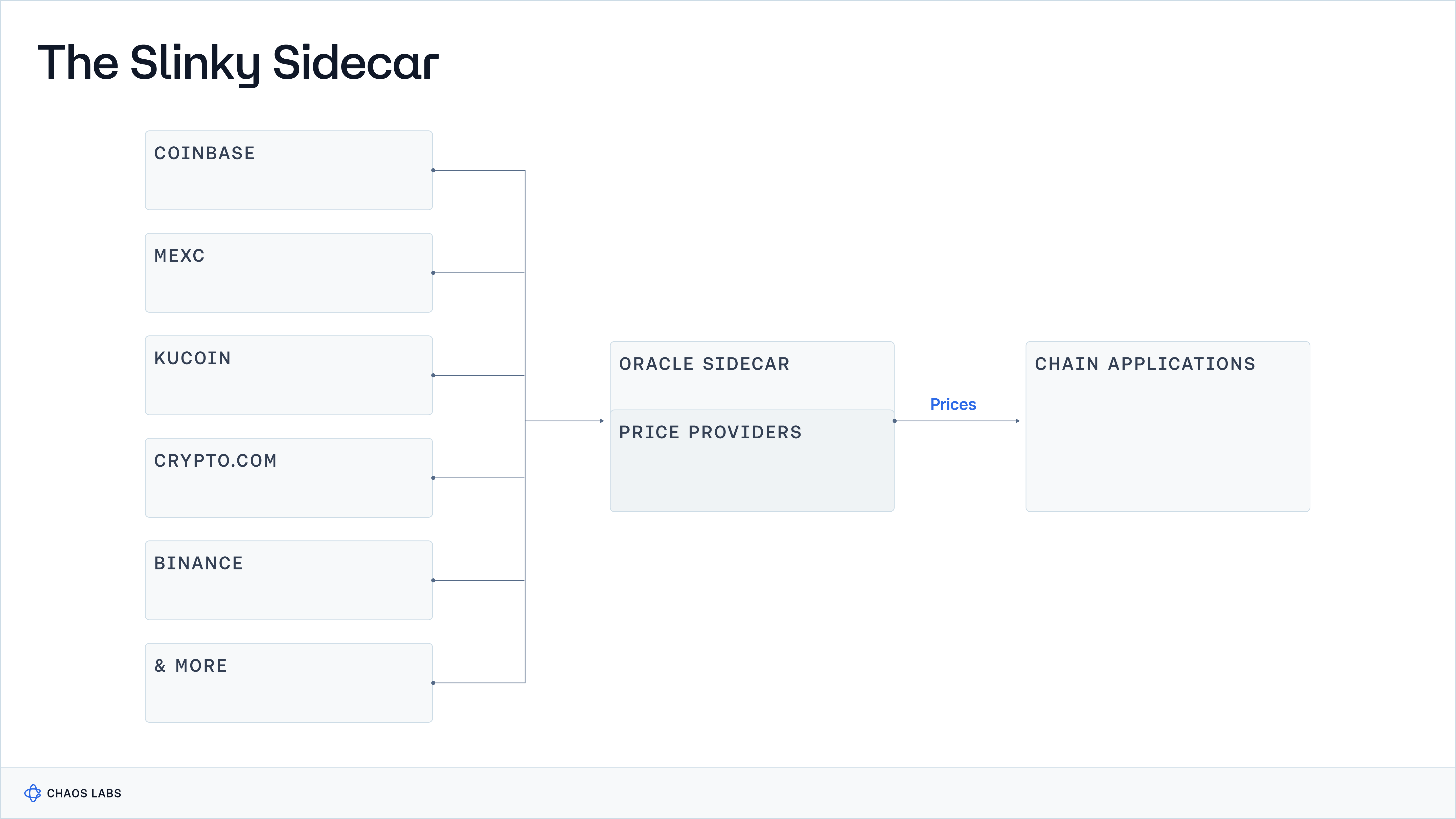
Security and Fault Tolerance
Slinky emphasizes security and fault tolerance by integrating closely with the blockchain in which it operates, embodying the concept of a "restaked" oracle. It relies on the chain's existing validator set for security, requiring a 2/3 stake weight for price updates, mirroring the consensus requirement for block commitments. This setup eliminates external dependencies, as Slinky injects price data directly into the chain, ensuring that price updates are atomic and guarding against Oracle attacks by leveraging vote extensions. These extensions, signed alongside validators' votes, include observed prices for currency pairs, necessitating over 2/3 of the validator set's agreement for block progression and price updates. While the standard security model needs 1/3 of stake manipulation to post incorrect prices, Slinky can enhance security by requiring 2/3 stake manipulation through additional validation checks, albeit with potential trade-offs in Oracle responsiveness during volatile market conditions. The operational excellence of validators is crucial in maintaining Slinky's reliability and accuracy, supported by comprehensive operational tools and support provided by Slinky.
Trade-offs Between Oracle Network Architectures
| DONs (Chainlink, Chronicle) | Oracle Chains (Pythnet) | Enshrined Oracles (Slinky) | |
|---|---|---|---|
| Price Computation | The Chainlink price computed each consensus round is a median of medians. In sum, Chainlink does not seek to take an opinion on the price; its goal is to transmit the median value reliably. Chronicle adopts the same approach. | Pyth offers an exponentially weighted moving average (EMA) price, seeking to more overtly assume the responsibility of being a price source, which carries its tradeoffs. | Slinky computes a stake-weighted median: a similar approach to Chainlink and Chronicle, but attributing a greater weighting to validators with a greater stake. |
| Transparency | Chainlink Labs showcases the Oracles participating in each price feed DON on data.chain.link, which can be verified on-chain. In contrast, the data providers from which Oracles stream remain a black box. Conversely, 12/20 of Chronicle’s validators are pseudonymous, though all data sources are transparent and verifiable on-chain. | The data providers list on Pyth’s website is transparent, however, there is no verifiable way to map public keys back to specific publishers. DWF Labs, for example, was announced by Pyth as a publisher in Nov. ‘22, only for Pyth to distance themselves publicly from DWF in January of this year. | Slinky's architecture promotes transparency by allowing the identification of validators involved in price aggregation, though it keeps the individual data sources private. |
| Trust Assumptions | Chainlink OCR is the core component that remains consistent across each Chainlink DON instance. Furthermore, the consistency and reliability of OCR are critical to the liveness of Chainlink price feeds. Chronicle’s consensus algorithm assumes a majority of validators are honest and not acting maliciously. | The availability of Pythnet’s service is contingent on Wormhole’s uptime. Recently, a Wormhole consensus failure caused an interruption to Pythnet’s service, impacting consuming applications for ~25 minutes. Pyth also relies on the consistency and reliability of the Pyth Oracle Program, which contained a bug responsible for miscalculating a TWAP in Oct. ‘21. | Slinky's architecture fundamentally relies on the consensus and operational reliability of its validators for its trust assumption. The system's effectiveness and the accuracy of its price feeds depend on the continuous uptime and correct functioning of these validators within the network. |
| Scalability | Chainlink’s multi-network architecture makes it more challenging to scale, given each price feed on each chain requires a dedicated DON. Chronicle’s monolithic architecture should, in theory, scale more efficiently, though it is still in an early expansion stage. | Pythnet’s hub-and-spoke architecture makes it highly scalable, allowing Pyth to support more than 450 price feeds across 50+ chains. | While Slinky's architecture benefits from the scalability afforded by the ABCI++ framework, blockchains that do not support ABCI++ or are not part of the Cosmos ecosystem may not seamlessly integrate with Slinky's architecture. |
Network Architecture Topology in Oracles
The oracle landscape showcases a variety of network topologies, each with its unique architecture and associated trade-offs tailored to specific use cases. The landscape of today’s oracle market is notably fragmented.
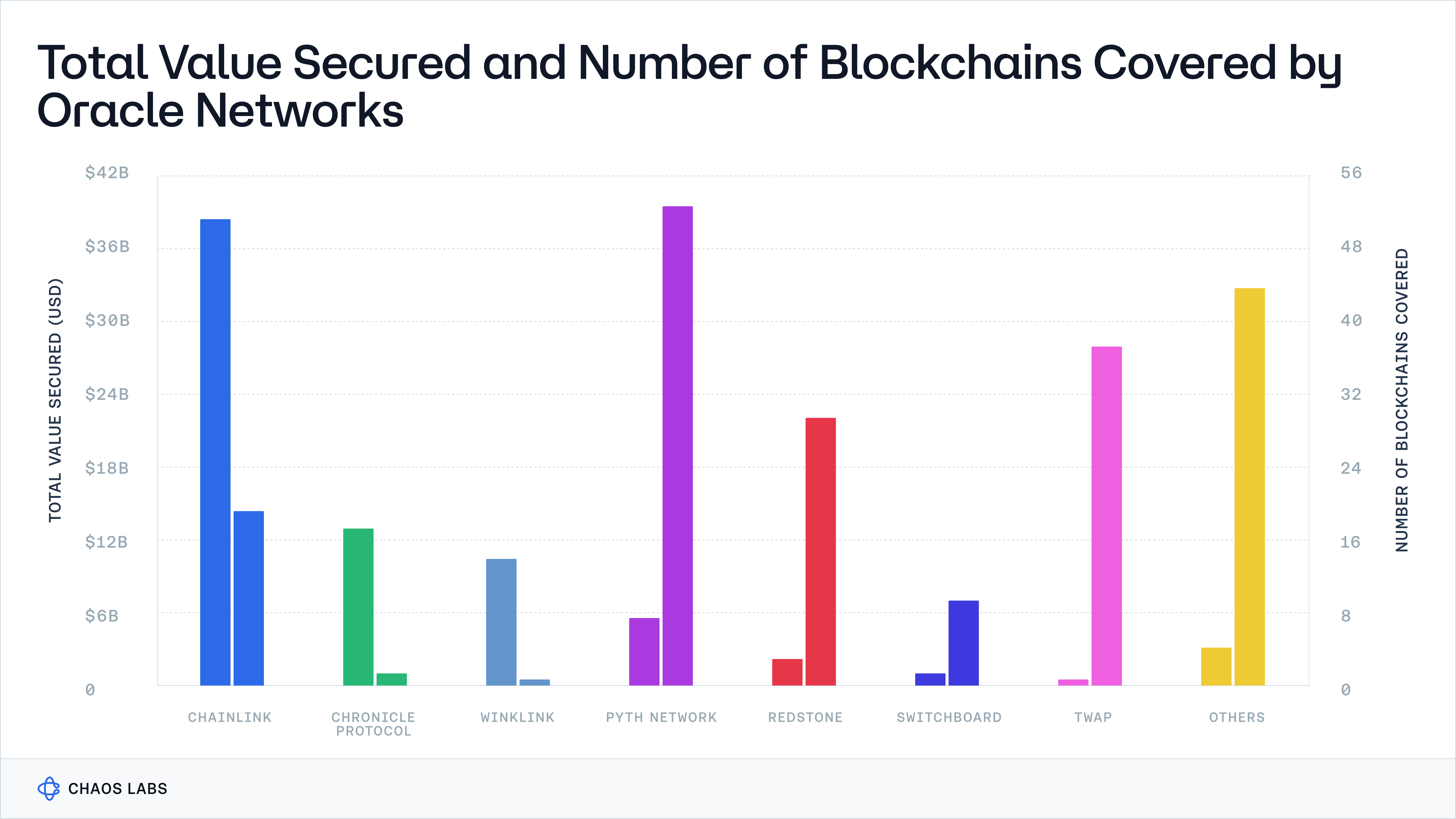
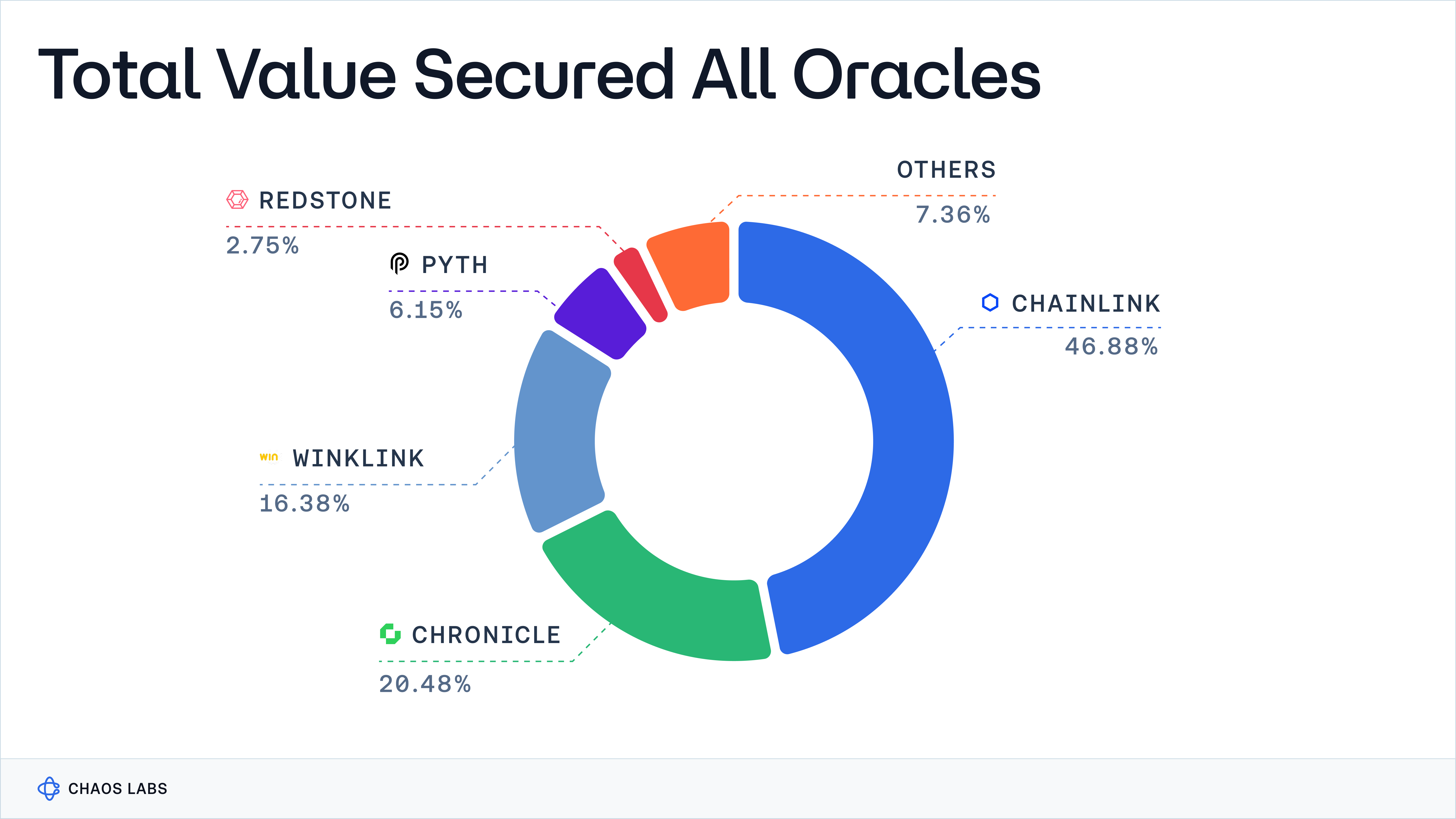
Although Total Value Secured (TVS) is dominated by oracle providers like Chainlink, Chronicle, and WINkLink, this concentration does not necessarily equate to market dominance or widespread adoption of a singular oracle architecture, as the TVS metric is heavily skewed and generated from a handful of applications like Aave, Maker, JustLend, and a few others.
For our analysis, we'll use TVS as a metric to identify the most production-ready oracles, focusing our attention on oracle providers with prevailing TVS. It's important to clarify that this segment of the series does not aim to endorse or conduct a comprehensive mechanism design audit of these platforms. Instead, our reviews are intended to highlight the diverse architectures currently deployed in production environments.
Before delving into the specifics of each architecture, we will first examine a generic network topology. This overview will illustrate the fundamental data flow and the interactions between different network component standards across all systems, providing a foundational understanding of Oracle systems operating at a basic level.
Component 1: Exchanges (Market Data Propagation)
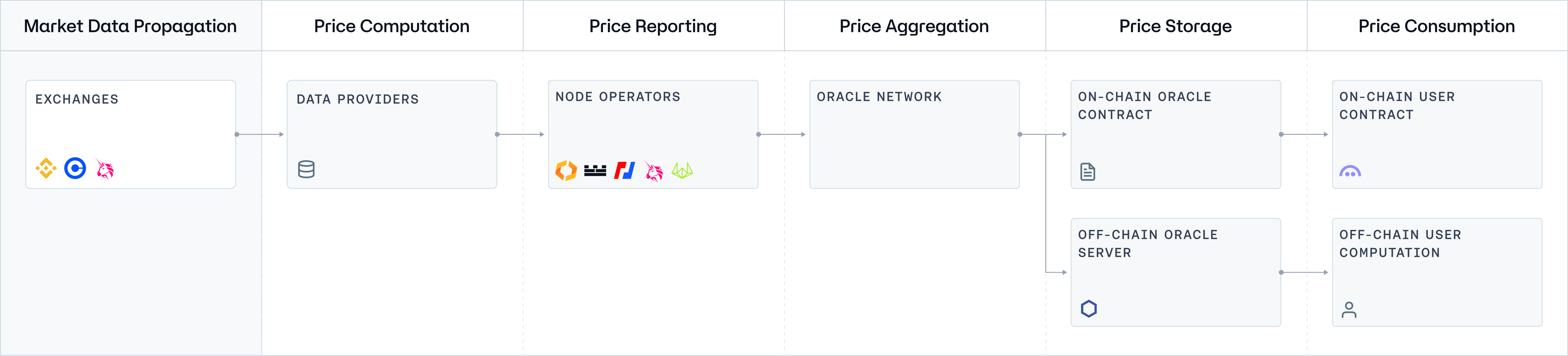
Exchanges serve as the foundational layer in the data supply chain for blockchain oracles, providing real-time market data across a wide range of assets. Exchanges facilitate the propagation of market data, acting as primary sources for price discovery. The information gleaned from these trading venues reflects the current market consensus on asset valuations, making it indispensable for the overall integrity of the Oracle network.
Exchanges are typically categorized into centralized (off-chain) and decentralized (on-chain), with the vast majority of trading volume taking place on centralized exchanges today (Spot: 94%, Perps: 99%).
For Oracle providers, two critical criteria when it comes to exchange coverage are:
- Coverage of the venues with the highest concentration of trading volume for the relevant market.
- The quality of market data exchanges can be provided on a reliable basis.
Market Data Grading
In the realm of oracles, understanding the intricacies of market data grading is crucial for judging oracle data quality.
Market data typically falls into a three-tiered system; the difference between the levels lies in the depth and breadth of market information provided.
- Level 1 data typically includes the best bid and ask prices and volume.
- Level 2 data provides more detailed market depth. It shows a snapshot of the order book for a particular market, including all bid and ask prices and the corresponding quantities.
- Level 3 data is more specialized and not as commonly available. It includes information on all individual bid and ask orders, sometimes called tick-level order book data.
These different levels of data provide varying degrees of insight into market liquidity and trading activity, with Level 3 being the most comprehensive and detailed.
Challenges with Sourcing High-Fidelity Data
There are hundreds of exchanges in the cryptocurrency market, but only a very limited number can reliably support the provision of Level 3 data. This challenges Oracle providers seeking to aggregate high-fidelity data with broad exchange coverage.
In addition to the age-old challenge of normalizing data from a diverse range of exchange sources, there is also the obstacle of harmonizing this with on-chain trade data from DEXes. This is why, similar to the emergence of Bloomberg and Refinitiv in traditional finance, market-leading Oracle Providers often source from data providers (aka vendors) such as Kaiko, Coin Metrics, and NCFX. Data providers inevitably add latency through the aggregation, harmonization, and sanitization of raw exchange data, which contributes to Pyth’s decision to primarily source from first-party data providers, like exchanges and market makers. This brings us to the next interval in the Oracle supply chain: data providers.
Component 2: Data Providers (Price Computation)
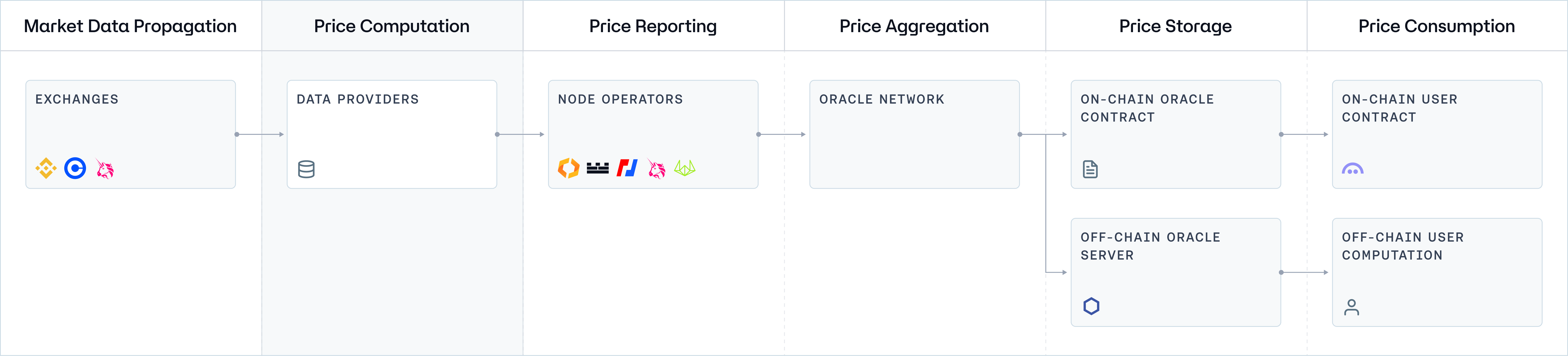
Data providers are pivotal in processing and refining the exchange's raw market data. They engage in price computation, which encompasses outlier detection to remove anomalies, data harmonization to ensure consistency across different sources, normalization to adjust for differences in scale, and sanitization to cleanse the data of errors and irrelevant information. This comprehensive process ensures that the data fed into Oracle networks is accurate, reliable, and reflective of true market conditions, safeguarding the Oracle service against manipulation and inaccuracies.
Data providers are generally categorized into first- and third-party; first-party data providers report data they’ve produced, versus third-party data providers (often referred to as “data aggregators”) who collect exchange data from many sources.
First-Party Data Providers
First-party data providers generate and supply data directly from their source without intermediaries. In blockchain Oracles, first-party data providers are typically exchanges or trading platforms that produce real-time market data, including prices, volumes, and order book information.
The benefits of using first-party data providers include direct access to primary, real-time data, ensuring high accuracy and timeliness. This direct data feed minimizes the risk of data tampering and delays, making it highly reliable for time-sensitive applications. However, the limitations include potential data silos, where Oracle's view is limited to the data from a single or limited number of sources, potentially introducing biases or blind spots. Moreover, relying solely on first-party data providers may expose Oracle to single points of failure, such as downtime or manipulation of the source platform.
An additional limitation arises from the potential conflict of interest when a market maker or trading firm participates in producing a price report that they might also be trading on downstream via the consuming application. This scenario can lead to concerns about the impartiality of the data, as these entities could theoretically manipulate the data to favor their trading strategies, undermining the trust and integrity of the oracle's data. Wash trading and other forms of manipulation are still prevalent in exchanges; participating exchanges could broadcast faulty trade data.
Third-Party Data Providers
Third-party data providers are intermediaries that collect, aggregate, and supply data from multiple sources, including first-party providers. They are crucial in enhancing the breadth and depth of data available to blockchain oracles, often enriching raw data with additional analysis or verification. The strengths of using third-party data providers include a broader perspective of the market, as they consolidate data from various sources, reducing the reliance on any single data point and mitigating risks associated with data silos and manipulation. However, the limitations are primarily related to potential latency in data delivery and the integrity of the aggregated data. Since third-party providers process and harmonize data from different sources, there's a risk of delays and inaccuracies in data reporting. Additionally, the quality of the aggregated data heavily depends on the methodologies and reliability of the third-party provider, which can vary widely and may not always be transparent.
The TradFi Case Study: First- vs Third-Party Data Providers
In traditional finance, data aggregators comprise 80% of the revenue generated from the market data industry. Popular data aggregators (aka data vendors) include Bloomberg and Refinitiv (now a subsidiary of LSEG), which have made their name by providing extension exchange coverage and abstracting away the challenges of aggregating this data. The other 20% comes directly from the exchange, the main customer base of which is high-frequency trading firms that require as close to real-time market data as possible and are happy to take on the burden of data aggregation themselves, applying proprietary algorithms throughout the aggregation process.
Component 3: Node Operators (Price Reporting)
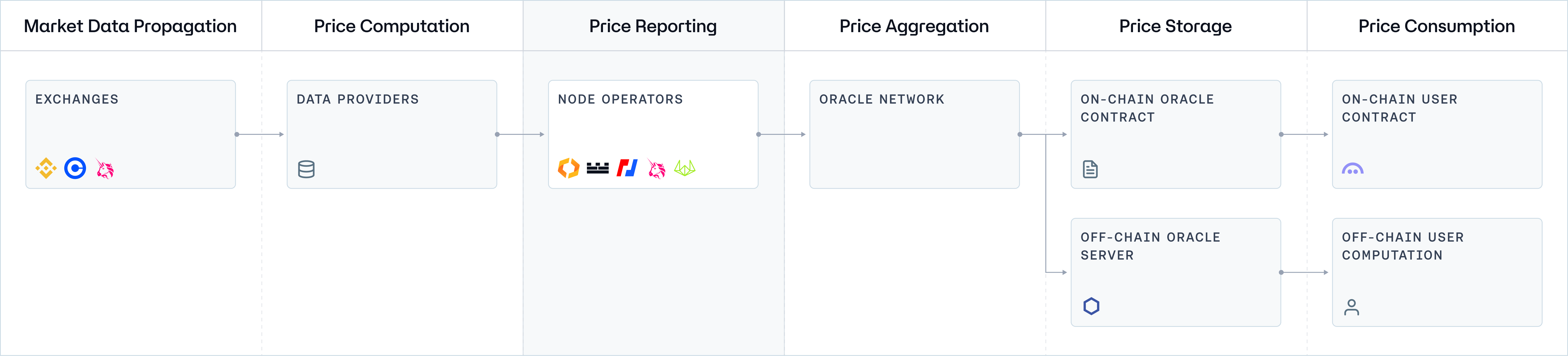
Node Operators are responsible for price reporting within the Oracle network. They collect and process data from a curated subset of data providers, applying a medianization technique to their observations to mitigate the impact of outliers or inaccuracies. Each node operator then submits a signed price report to the Oracle network, attesting to the integrity of the data based on their independent assessment. This decentralized data collection and reporting approach enhances the security and resilience of the Oracle network by distributing trust among multiple independent actors.
Node Operator Diversity
Node operator diversity is critical for the robustness and integrity of price oracles, as it ensures the resilience of the oracle network against single points of failure and targeted manipulation. A diverse set of node operators, hailing from different geographical locations, operating with varying infrastructure, and utilizing independent data sources enhances the network's decentralization. This variety makes it exceedingly difficult for any malicious actor to compromise the Oracle system, as manipulating the data would require subverting a significant proportion of the diverse operators. Furthermore, diversity among node operators ensures a wide range of data inputs and methodologies for price reporting, leading to a more accurate and representative consensus price. This is essential for maintaining trust in the Oracle service among users and applications that rely on its data, as it guards against biases and ensures the reliability of the information provided.
Component 4: Oracle Network (Price Aggregation)
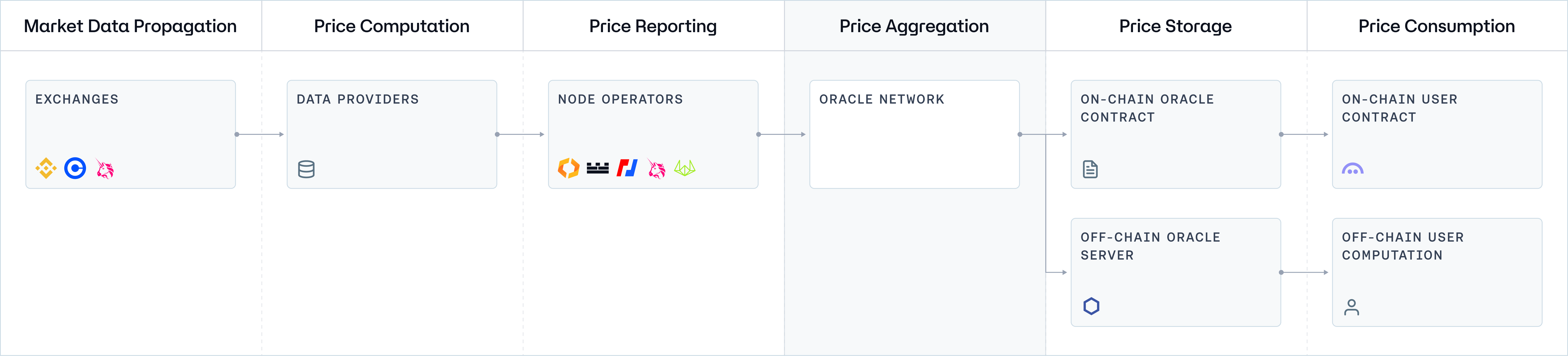
The Oracle Network aggregates the data supply chain, synthesizing individual price reports from node operators into a single, consolidated price report. This process is facilitated by a consensus mechanism, which ensures that only data agreed upon by a quorum of oracles is included in the final report. The resulting aggregated price should be a robust and reliable reflection of market conditions, incorporating multiple independent observations and mitigating the risk of manipulation or single points of failure. In this context, it's crucial to understand the number of oracles participating in consensus and the minimum threshold required for generating a valid report.
Opinionated vs. Unopinionated Oracle Providers
Oracle networks can be distinguished into opinionated and unopinionated (or "messenger") oracles. Opinionated oracles assess and refine the data they provide according to predefined criteria, offering tailored accuracy but potentially introducing subjectivity that may affect data integrity. In contrast, unopinionated oracles deliver data without alteration, preserving objectivity but requiring consuming applications to handle data validation and interpretation, which could lead to increased on-chain processing demands. This distinction presents a trade-off between customized data accuracy and the neutrality and simplicity of data transmission, influencing the choice based on the specific needs of the consuming application.
There is a split opinion on whether the price aggregation component should be opining on the calculation of the price being submitted or just relay their observations, simply taking the median of the various data sources they’re streaming from.
Component 5: Price Storage
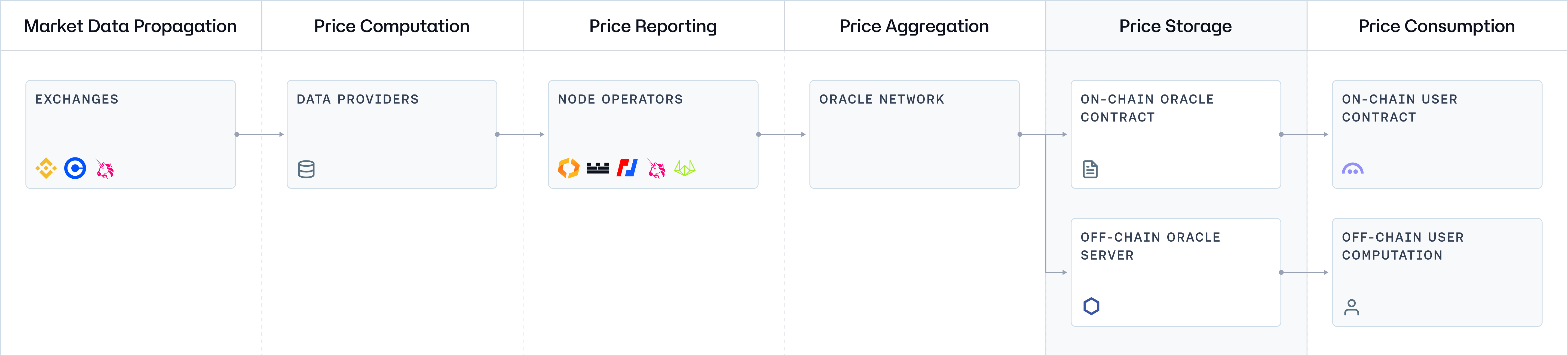
The storage and accessibility of price data within Oracle systems are crucial for the functionality and reliability of blockchain applications. Depending on the architecture, price storage can be implemented via on-chain Oracle contracts for direct blockchain access or through off-chain servers for efficiency and scalability, each with advantages and challenges.
On-chain Oracle Contract
On-chain oracle contracts are decentralized repositories for storing price data directly within the blockchain. These smart contracts collect, aggregate, and store price information from Oracle networks, making them readily accessible to consuming applications through blockchain transactions. This method ensures that price data is immutable, transparent, and tamper-proof, given its integration into the blockchain's ledger. Consuming applications can directly read the stored price data from these on-chain contracts, allowing for seamless integration and interaction with decentralized financial instruments and other smart contract functionalities. The primary advantage of this mechanism is the inherent security and trustlessness of blockchain technology, ensuring that data integrity is maintained. However, storing data on-chain can be costly due to gas fees and may lead to scalability issues as the demand for data storage increases.
Off-chain Server
Off-chain servers represent an alternative approach to price storage, where price reports are cached off the blockchain and can be retrieved on-demand through a pull-style Oracle architecture. This mechanism involves Oracle networks processing and storing data on external servers, consuming applications, and requesting the latest price reports as needed. This approach significantly reduces the burden on the blockchain, leading to lower transaction costs and enhanced scalability. Off-chain storage also allows for more complex data processing and analytics that would be impractical to perform on-chain due to gas constraints. However, the trade-off includes increased centralization risks and reliance on the security and availability of the off-chain infrastructure. While this method can offer more efficiency and flexibility, it requires robust security measures and trust in the Oracle provider to ensure data integrity and availability.
Decentralized third-party or in-house keepers provide a novel approach to on-demand price report retrieval from off-chain servers. They act as intermediaries, ensuring smart contracts access the latest data. This method blends off-chain efficiency with on-chain security, leveraging automated bots or networks to fetch and update prices and balancing computational flexibility with decentralized trust.
Component 6: Price Consumption
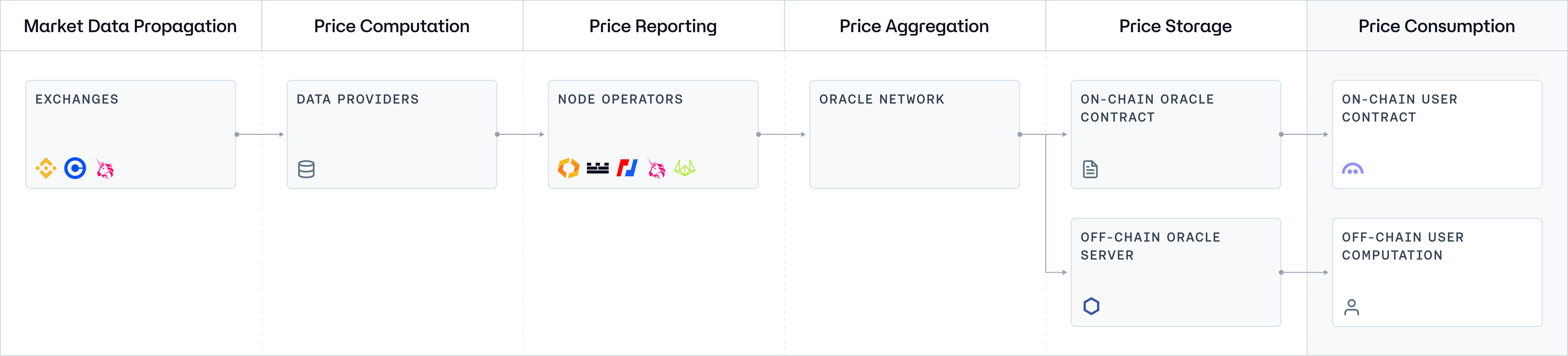
Consuming price data from oracles is a pivotal process that enables blockchain applications and off-chain systems to make informed, data-driven decisions. For decentralized applications, this can be achieved through direct integration with on-chain user contracts or via off-chain servers for more complex computations and analyses, each method offering distinct benefits and considerations.
On-chain User Contract
On-chain user contracts consume Oracle prices directly on the blockchain, integrating real-time data into intelligent contract functionalities. This mechanism allows decentralized applications (dApps) to automate actions based on the latest market conditions, such as executing trades, settling financial instruments, or managing collateral ratios without manual intervention. The primary advantage of consuming prices on-chain is the seamless and trustless interaction with data, ensuring actions are based on immutable and verifiable information. However, this approach may be constrained by the gas costs associated with on-chain transactions and the processing limitations of smart contract platforms, potentially affecting the efficiency and scalability of applications that require high-frequency data updates.
Off-chain User Computation
Alternatively, off-chain servers can consume Oracle prices off the blockchain, utilizing this data for computations that are too resource-intensive for on-chain execution or require a level of privacy not afforded by the blockchain. This setup is often used in systems that process large volumes of data quickly or in complex algorithms that inform trading strategies, risk assessment, and other financial analyses. Consuming prices, off-chain allows for greater computational flexibility and efficiency, free from the gas costs and execution limits of blockchain networks. However, this method introduces a dependency on the security and reliability of off-chain infrastructure and requires mechanisms to ensure the integrity and trustworthiness of the consumed data when making decisions that affect on-chain assets or operations.
What’s Next
We've concluded Chapter 1 on Oracle Network Architectures and Topologies. Next, our series progresses to Chapter 2 on Price Composition Methodologies! Keep an eye out for our latest updates and dive deeper into the intricate world of Oracle security with us!
Introducing Aave's Chaos Labs Risk Oracles
In the fast-paced and volatile environment of DeFi, managing risk parameters across Aave's extensive network—spanning over ten deployments, hundreds of markets, and thousands of variables such as Supply and Borrow Caps, Liquidation Thresholds, Loan-to-Value ratios, Liquidation Bonuses, Interest Rates, and Debt Ceilings—has evolved into a critical, yet resource-intensive, full-time endeavor. Chaos Labs aims to streamline this paradigm by integrating Risk Oracles to automate and optimize the risk management process, achieving scalability and near-real-time risk adjustment capabilities.
Oracle Risk and Security Standards: An Introduction (Pt. 1)
Chaos Labs is open-sourcing our Oracle Risk and Security Standards Framework to improve industry-wide risk and security posture and reduce protocol attacks and failures. Our Oracle Framework is the inspiration for our Oracle Risk and Security Platform. It was developed as part of our work leading, assessing, and auditing Oracles for top DeFi protocols.
Risk Less.
Know More.
Get updates on our research, product, and launch.