Oracle Risk and Security Standards: Data Replicability (Pt. 4)
Introduction
Reference chapters:
- Oracle Risk and Security Standards: An Introduction (Pt. 1)
- Oracle Risk and Security Standards: Network Architectures and Topologies (Pt. 2)
- Oracle Risk and Security Standards: Price Composition Methodologies (Pt. 3)
- Oracle Risk and Security Standards: Price Replicability (Pt. 4)
- Oracle Risk and Security Standards: Data Freshness, Accuracy, and Latency (Pt. 5)
The previous chapter in this series outlined Oracles' methods for sourcing, filtering, and aggregate asset prices. This chapter focuses on how they guarantee the replicability of those methodologies.
Data replicability is the capacity for third parties to independently recreate an Oracle’s reported prices. This requires transparency into two critical components of Oracle’s system: its data inputs and aggregation methodology.
Ensuring data replicability is crucial for maintaining the integrity and trustworthiness of an Oracle system. By providing clear insights into the data sources and the processes used for data aggregation, Oracles can offer verifiable and consistent price information. This transparency not only strengthens the reliability of the data but also fosters greater confidence among users, who can independently verify the accuracy of the reported prices.
Below, we outline and discuss the technical and operational measures that enable replicability.
Understanding Data Replicability
Data replicability is a cornerstone for the credibility and functionality of Oracle services in DeFi. Without it, users must blindly trust the Oracle's output, contrary to the core principles of DeFi: decentralization and trustlessness. Transparent data processes ensure that all stakeholders can independently confirm the accuracy and reliability of the data, thereby enabling a more secure and trustworthy ecosystem.
Data replicability also plays a vital role in dispute resolution and auditability within DeFi systems. When users or stakeholders have the ability to replicate data, it becomes easier to identify discrepancies and resolve conflicts. This capability is particularly important in financial transactions where the stakes are high, and even minor errors can lead to significant financial losses. Replicability provides a means for external auditors to verify that the data being used by smart contracts is accurate and that the aggregation methodologies are sound and unbiased. This level of scrutiny is necessary to prevent manipulation and to ensure that the Oracle’s data remains consistent and reliable over time.
Furthermore, achieving data replicability involves several key considerations and technical nuances that are not immediately apparent. One such consideration is the selection of data sources. Oracles must choose reputable and diverse sources to minimize the risk of data corruption, bias, and manipulation. Additionally, the methodologies used to filter and aggregate this data must be robust and transparent, allowing for independent validation. This often requires detailed documentation and open access to the algorithms and processes used by the Oracle. Another nuance is the need for real-time data validation and error correction mechanisms, which can detect and address anomalies before they affect outputs. These considerations underscore the complexity of ensuring data replicability and highlight the need for continuous monitoring and improvement of Oracle systems.
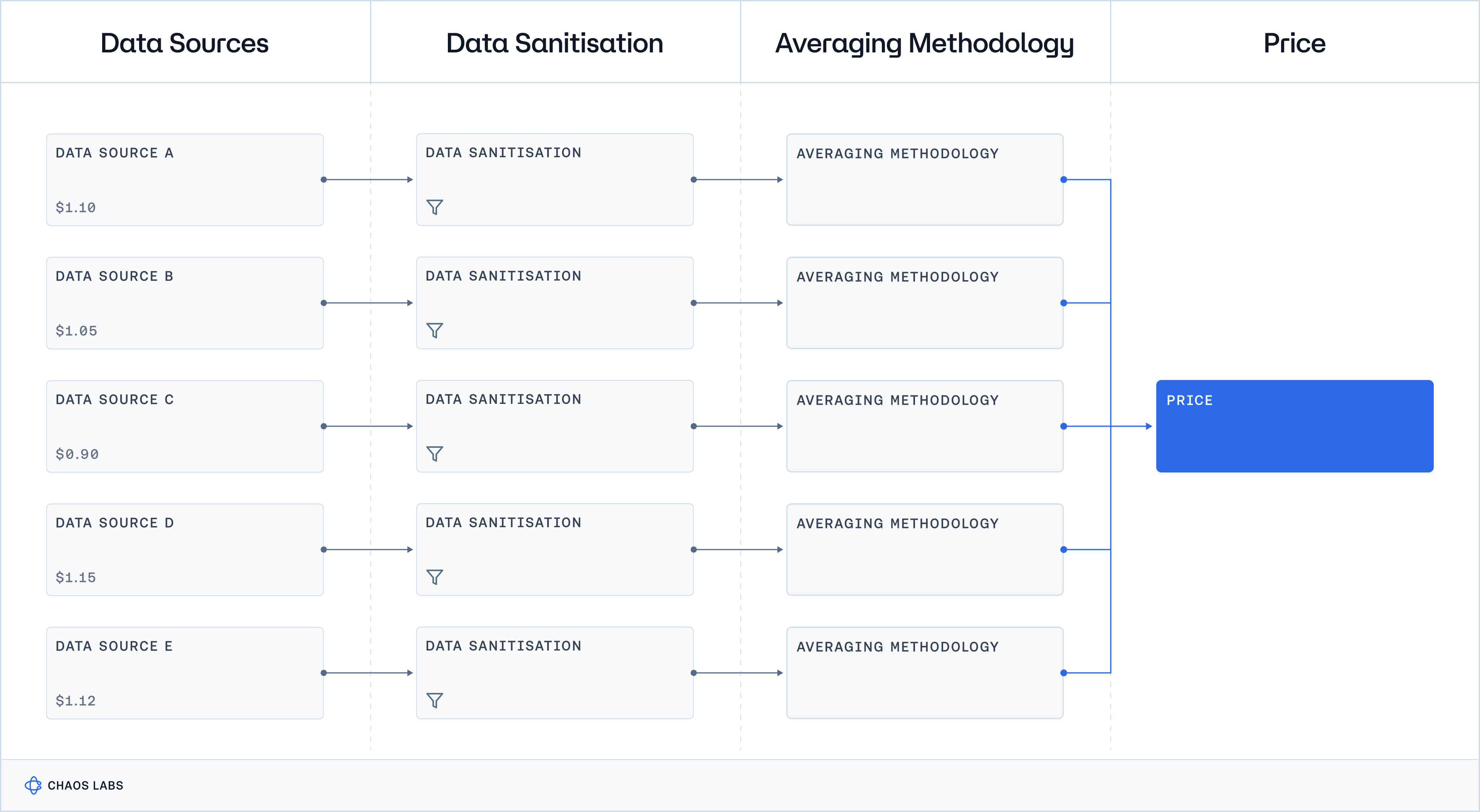
Tracing Inputs for Price Determination
Tracing inputs for price determination is a fundamental aspect of ensuring the transparency and reliability of Oracle services. Oracles gather data from various sources, including exchanges, market feeds, and other financial data providers, to compile a comprehensive dataset. This dataset forms the basis for the price reports that drive decisions in DeFi applications. To trace these inputs, Oracles must implement robust logging and documentation practices that detail every step of the data collection and aggregation process. This includes recording the origin of each data point, the time of data collection, and any transformations or filtering applied to the raw data. By providing a clear and detailed trace of the data inputs, Oracles enable users and developers to verify the authenticity and accuracy of the reported prices independently.

Moreover, the technologies and methods used to trace data inputs play a critical role in replicability. Blockchain technology itself offers a transparent and immutable ledger that can be used to record data input transactions. Advanced cryptographic techniques, such as hashing and digital signatures, can be employed to verify the integrity of the data at every stage. These technologies ensure that any attempt to alter or tamper with data inputs can be easily detected. Additionally, open-source frameworks and tools for data traceability allow developers to scrutinize and audit the processes used by Oracles, further reinforcing the system's transparency and trustworthiness.
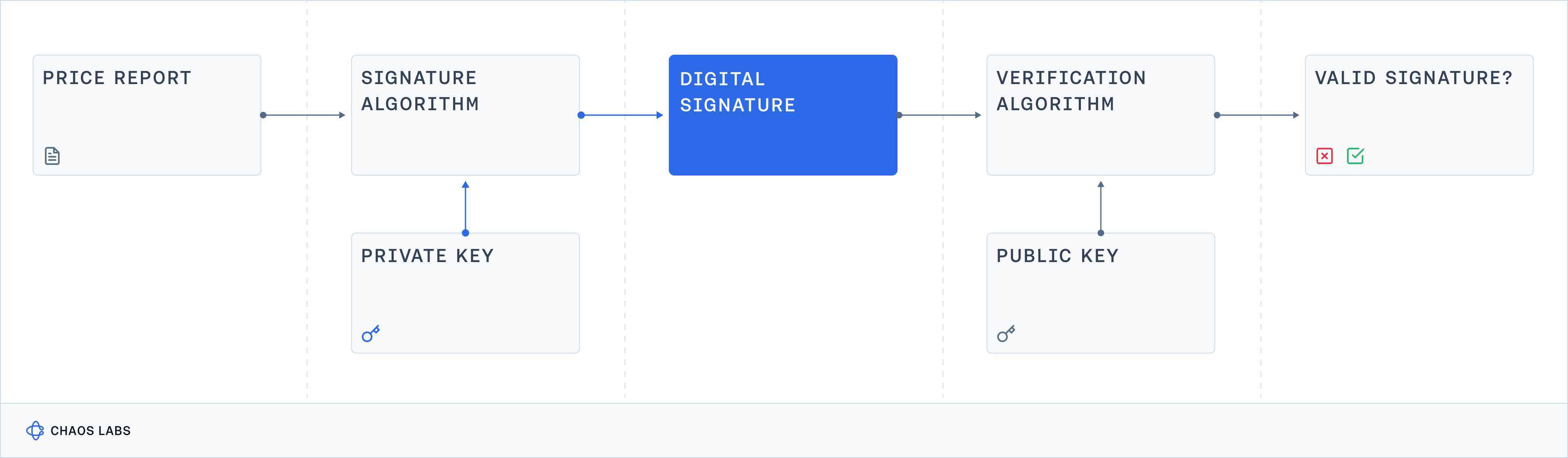
Digital signatures protect data integrity in a manner similar to a courier carrying a briefcase handcuffed to their wrist. Just as the handcuff ensures the briefcase cannot be opened until the courier reaches their destination and receives the key, digital signatures ensure that data cannot be altered without detection. The "handcuff" in this analogy is the cryptographic hash created by the digital signature, which locks the data in its original state. If someone attempts to tamper with the data during transmission, it’s as if they’ve tried to break the handcuff; any change in the data would alter the hash, signalling to the recipient that the data has been compromised and should be considered illegitimate. Additionally, just as the courier's identity can be verified by those expecting the delivery, digital signatures authenticate the sender, ensuring that the data originates from a legitimate source. This mechanism provides a robust framework for maintaining data integrity, authenticity, and non-repudiation, making digital signatures a vital tool in securing data transactions.
First- vs Third-Party Data Sourcing
A critical distinction among oracle providers lies in their use of first-party versus third-party data sources. First-party data originates from market makers or trading firms that submit price quotes reflecting their potential willingness to transact. However, this data lacks replicability because it can be difficult to verify whether the firm would have genuinely quoted that price at that time, especially if the price deviates significantly from exchange-observed prices. In contrast, third-party data is aggregated from observed market activity and disseminated by data aggregators, which often includes data sourced directly from exchanges. As neutral entities, exchanges compile actual trades and quotes from a broad range of market participants, making their data more transparent and verifiable. One key advantage of exchange-sourced data is that trades come with unique identifiers, allowing for precise reconstruction of any calculation at any point in time. This contrasts with quotes, where not every quote may have a unique identifier, making it harder to reproduce a price if needed. This ability to audit and replicate exchange-derived data gives third-party sources an edge in terms of price accuracy and reliability, a task that is considerably more challenging for first-party data providers. Ultimately, the ability to trace inputs for price determination not only enhances the replicability and transparency of Oracle services but also makes DeFi ecosystems more robust.
| Description | Sources | Data Used to Derive Price | |
|---|---|---|---|
| First-Party Data | Comes directly from market participants, such as market makers or trading firms, and reflects their individual pricing models or quotes. | Market Makers, Trading Firms | Quotes |
| Third-Party Data | Collected from external sources, not originating from the data supplier, and is typically aggregated from actual market activity across various participants. | Exchanges, Data Aggregators | Trades and Quotes |
Challenges and Solutions in Data Replicability
Achieving data replicability in Oracle services is fraught with several challenges, the foremost being the diversity and reliability of data sources. For instance, one data source might update cryptocurrency prices every minute, while another updates hourly, leading to discrepancies in reported values. Additionally, sources may have different methodologies for calculating prices—such as using the latest trade, a volume-weighted average, or the midpoint between bid and ask prices—introducing further inconsistencies. Some sources might also be prone to biases, like exchanges with lower liquidity reflecting more volatile prices. These variations make it difficult for Oracles to aggregate data consistently, complicating the task of ensuring that the final output can be reliably replicated by third parties.
Additionally, the aggregation process itself can introduce complexities, as different methodologies might yield varying results. Ensuring that the aggregated data remains transparent and verifiable is a significant hurdle that requires careful consideration and robust methodologies.
To address these challenges, Oracle services can adopt several innovative solutions and best practices. One effective approach is to implement a multi-layered data verification system. This system can cross-check data from multiple independent sources, ensuring that anomalies or discrepancies are identified and resolved promptly. Employing machine learning algorithms and statistical models can significantly enhance data aggregation accuracy. For example, algorithms like isolation forests or support vector machines (SVMs) can detect anomalies in real-time by identifying unusual patterns in large datasets. These tools can flag suspicious price spikes or craters in crypto markets that deviate from historical trends, enabling Oracles to filter out unreliable data.
Establishing clear and transparent aggregation methodologies is also crucial for enhancing data replicability. Oracle services should provide detailed documentation of their data collection and aggregation processes, allowing users and developers to understand and replicate the steps involved; open-source software and community-driven development may also be beneficial. Regular audits and third-party assessments, (e.g. GMX Oracle Audit), can further bolster trust in the data provided by Oracles, ensuring that they adhere to high standards of accuracy and reliability.
Implications for Oracle Reliability and User Trust
When users and developers can independently verify the data provided by Oracles, it significantly enhances the perceived reliability of these services. Reliable Oracles are essential for the proper functioning of DeFi applications, providing the accurate and timely data required for smart contracts to operate correctly. Without replicability, users are left to trust the Oracle without verification, which contradicts the foundational principles of decentralization and transparency inherent in blockchain technology.
Furthermore, data replicability mitigates risks associated with data manipulation and errors. In a decentralized ecosystem where financial transactions and automated decision-making rely heavily on data accuracy, any discrepancy can lead to significant financial losses and undermine user confidence. By ensuring that data can be replicated and verified independently, Oracles can provide a safeguard against potential fraud and errors. This transparency in data processes not only protects users but also enhances the overall security and robustness of DeFi platforms.
Ultimately, data replicability is more than a technical feature It can be a cornerstone for user confidence and trust in decentralized applications. Full oracle replicability can, however, also have unexpected consequences. If an oracle is fully replicable and transparent, frontrunning can be an even bigger problem. Actors could replay the entire oracle logic themselves faster than the oracle and reliably front run the pricing outcomes. As the DeFi space continues to grow and evolve, the need for transparent, verifiable, and reliable data grows and should be balanced with replicability risks. Oracles can utilize replicability to stand out among others, attracting users and fostering a more transparent, secure ecosystem. The broader impact of data replicability is thus twofold: it enhances the operational reliability of oracles and, perhaps more importantly, can instil a sense of trust among users. This trust is fundamental for the widespread adoption and success of DeFi, making data replicability an essential aspect of any Oracle service.
Case Studies
Chainlink
Data Sourcing
Chainlink’s decentralized network of oracle nodes sources data from a unique subset of data aggregators. Each node in a DON can source its data from different sources than any other. While many of the data aggregators contributing to Chainlink price feeds are known, the exact data aggregator set for a given feed remains unnamed. These data aggregators obtain raw market data from a variety of centralized and decentralized exchanges, each applying its own proprietary exchange selection framework and data sanitization process. The exchange selection frameworks, data sanitization processes, and averaging methodologies adopted by each data aggregator remain private and opaque to downstream consumers of Chainlink price feeds. This opacity does not allow for data replicability, as third parties cannot independently trace and verify the exact sources of the data used by Chainlink oracles.
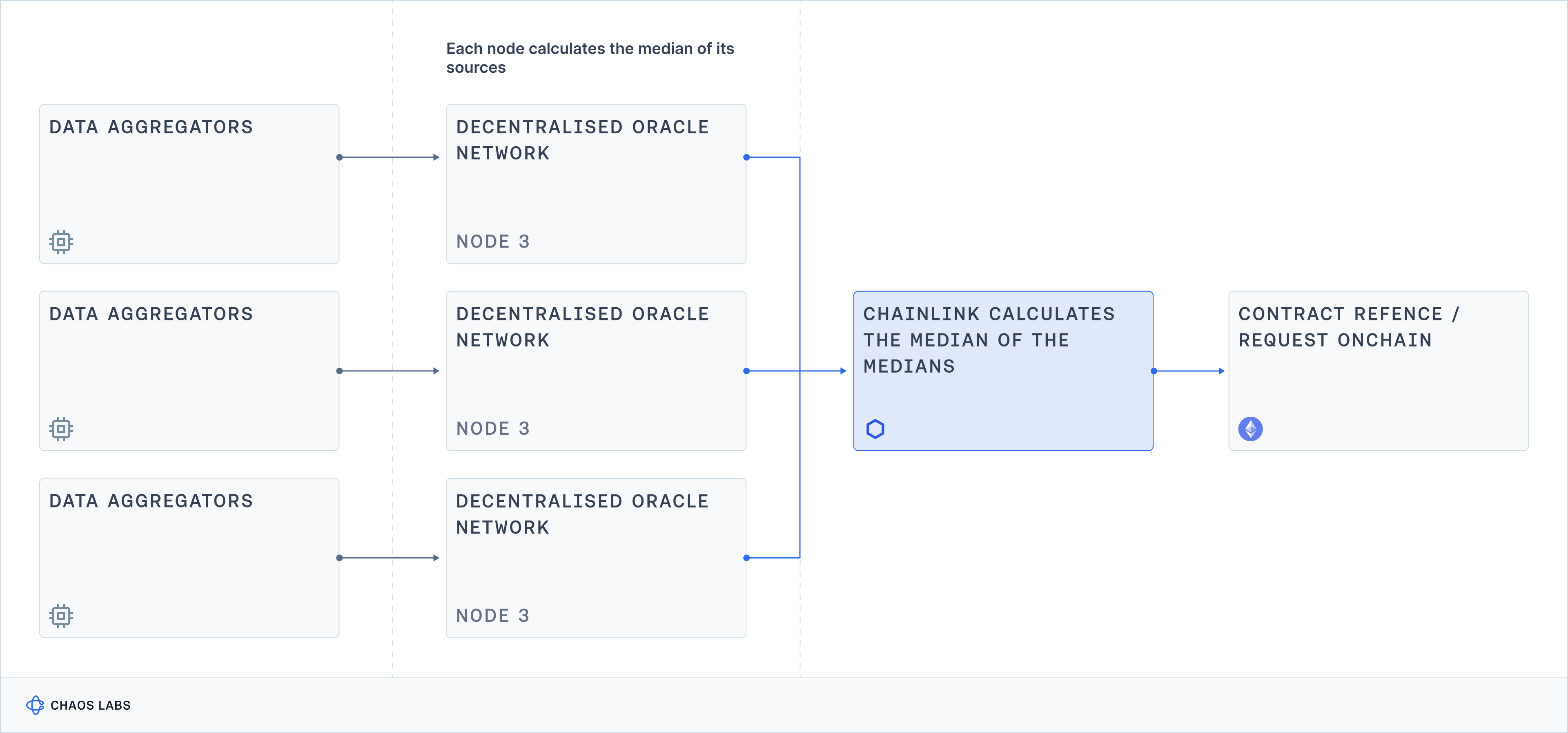
Data Filtering & Aggregation
Chainlink OCR, the consensus mechanism run by Chainlink’s decentralized Oracle networks, computes the median price of all signed price observations submitted by individual Oracle nodes. Apart from the calculation of the median value, no filtering algorithm is applied to the price observations submitted by participating Oracle nodes. The calculation of the median can be verified on-chain in the aggregate price report, as the full list of signed price observations from each participating Oracle node is featured in the report. This transparency in the aggregation process allows third parties to replicate the median calculation, but the inability to verify the original data inputs limits the overall replicability of the reported prices.
Data Publishing & Archiving
There is a clear audit trail of every historical Chainlink price report published on-chain; these reports are discoverable through block explorers and can be easily verified. Chainlink also offers a front-end solution, data.chain.link, which features a user-friendly interface for accessing and verifying these reports. This transparency in data publishing and archiving ensures that users can trace the historical data and verify the aggregation methodology, contributing to data replicability. However, the lack of transparency in the initial data sourcing process remains a limiting factor for full replicability.
Pyth
Data Sourcing

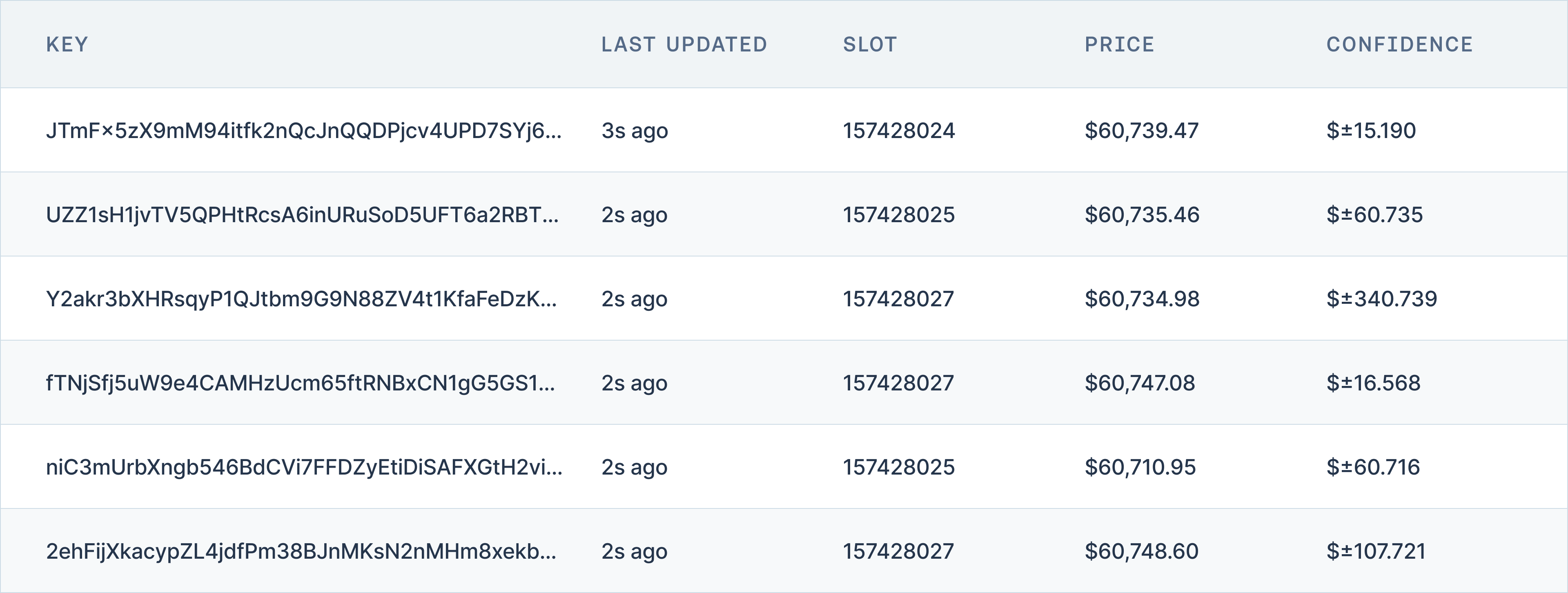
Pyth price data is sourced from a decentralized network of publishers that comprise Pythnet, Pyth’s permissioned SVM app-chain. While the list of these publishers is available on the Pyth website, the individual data providers cannot be directly verified on Pythnet. This lack of transparency presents challenges for data replicability, as independent third parties cannot fully trace and verify the exact data sources contributing to Pyth’s reported prices. The inability to audit the original data inputs limits the ability to independently replicate the reported data.
Data Filtering & Aggregation
Pyth’s aggregation process aims to ensure data integrity and reliability by using a combination of median calculations and confidence intervals. While the specific algorithms used—such as incorporating publisher confidence intervals and utilizing an adapted Exponential Moving Average (EMA)—are designed to enhance data robustness, the key focus for replicability is the transparency of these processes. Pyth publishes detailed methodologies on how data is aggregated, allowing third parties to understand the process. However, without access to the exact data inputs, independent replication and verification remain incomplete. This transparency in the aggregation process supports replicability, but the lack of verifiable data sources remains a significant limitation.
Data Publishing & Archiving
Pyth maintains a comprehensive history of all generated price reports on Pythnet, which are visible and verifiable, providing a clear audit trail. This transparency in historical data allows users to examine the accuracy and provenance of reported prices. However, for true data replicability, the ability to independently verify both the aggregation methodology and the original data inputs is essential. While Pyth provides transparency in its aggregation processes, the lack of verifiable data inputs limits the extent to which third parties can fully replicate and validate the oracle's reported prices.
Chronicle
Chronicle Protocol offers an open and permissionless dashboard called The Chronicle, which allows users to view both real-time and historical data reported by the Chronicle Protocol. The authenticity of the data displayed on the dashboard can be cryptographically verified, ensuring full transparency of the final values reported by the Oracle network and the validators who attested to the data's accuracy. The dashboard also provides detailed information on the sources, and all available data feeds, including the addresses, identities, and real-time reported off-chain data of each validator, as well as the total dollar value secured (TVS) by the network.
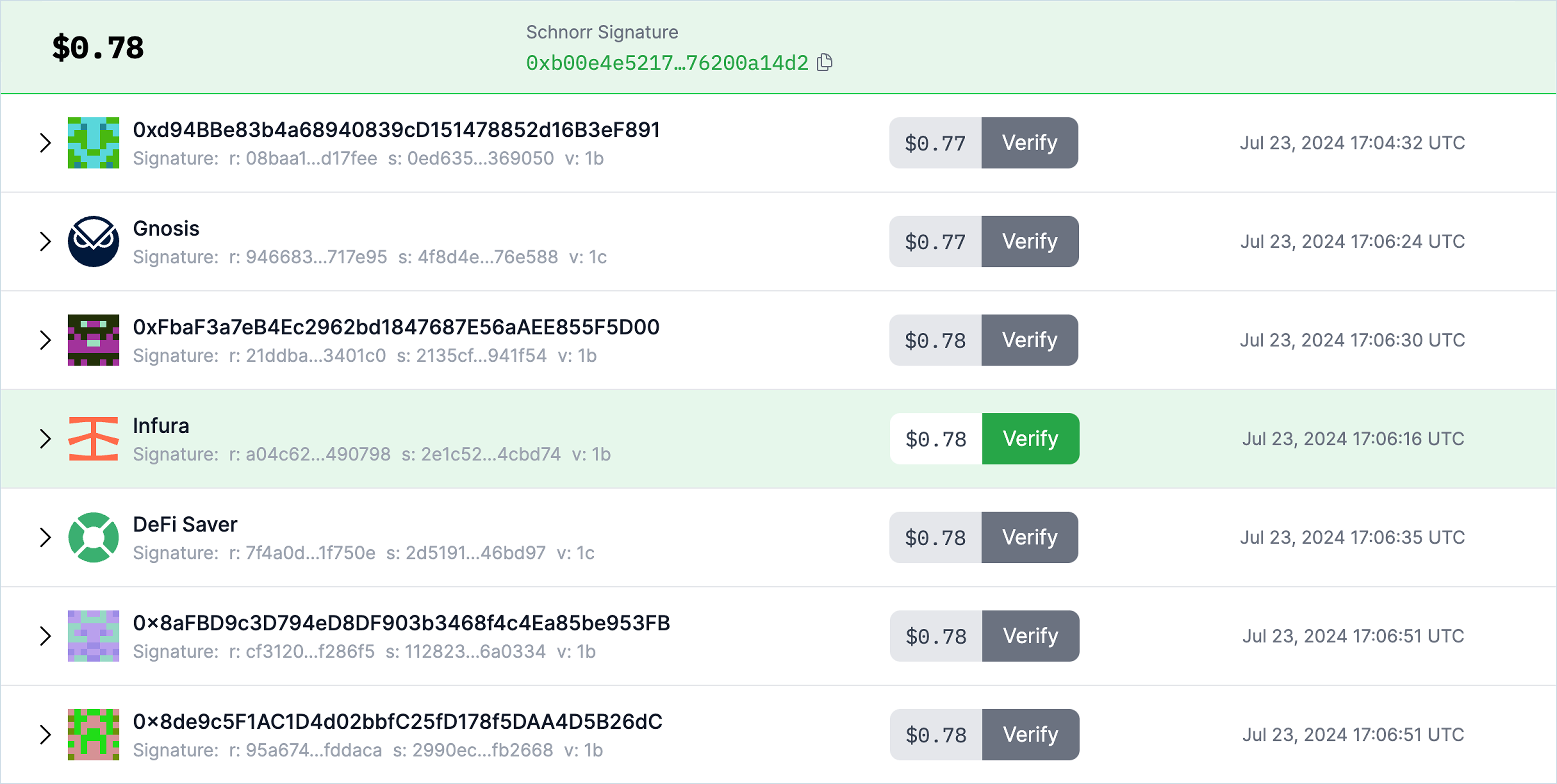
Data Sourcing
Chronicle provides full visibility into all data sources used to determine each price report, both on and off chain, for every Oracle/Price Feed. The source data is verifiable and unique to each validator and includes the venue where the value has been derived, such as the DEX or CEX; the individual token pairs or markets that have been included in the data model, such as BTC/USD, BTC/USDT, BTC/ETH, etc.; and the value reported by each venue.
Users can visualize these data sources using the Dashboard, which allows for comprehensive tracing and verification of each data input. This level of transparency ensures that third parties can independently verify the sources of data, a critical component for ensuring data replicability.
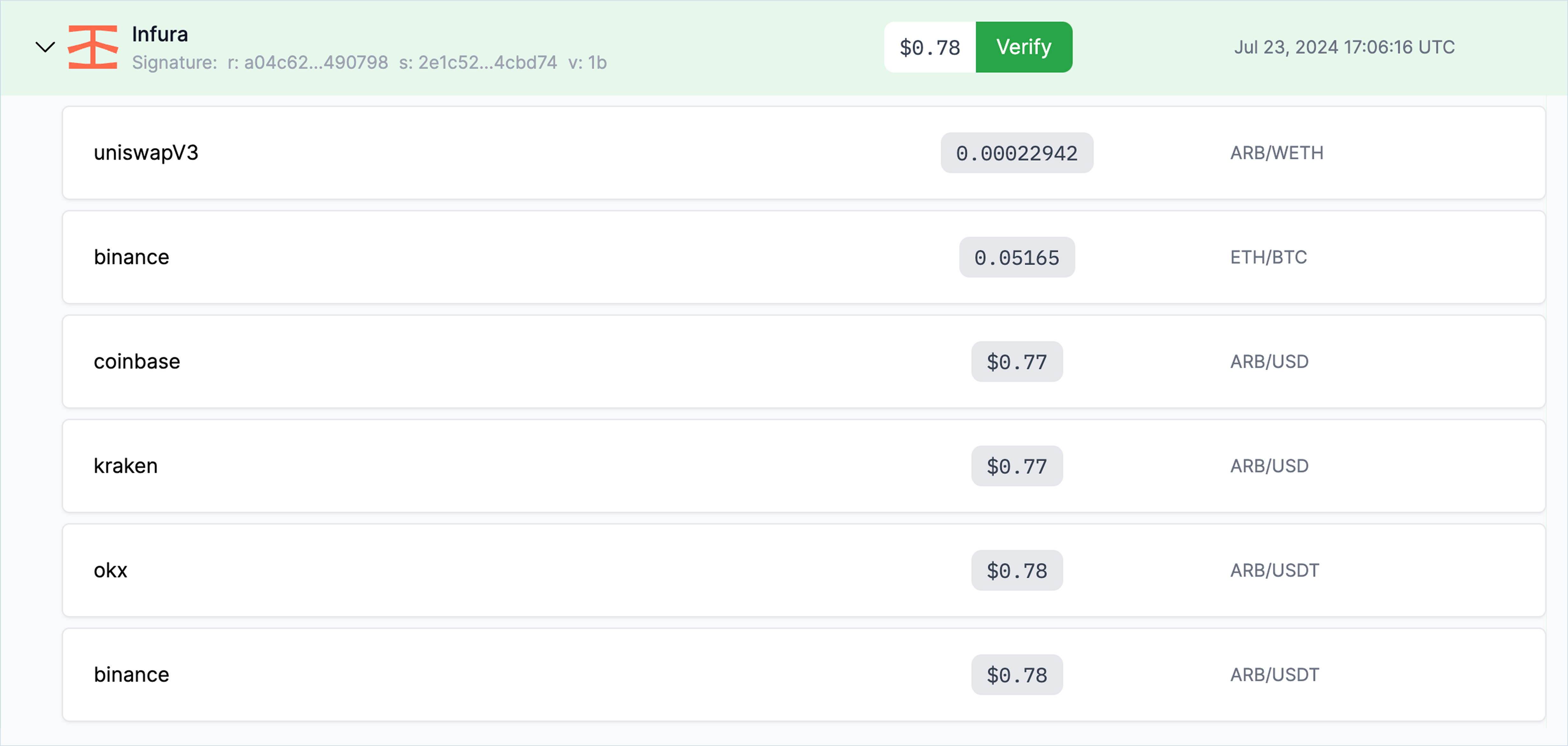
Data Filtering & Aggregation
Chronicle employs a median of medians aggregation methodology to eliminate outliers and determine the final value in the price report consumed by users. A minimum number of validators, called a quorum, must report back within a certain time window before a price report can be generated. Data is minimally filtered, aiming to be as pure a representation of the aggregated market value as securely possible.
Each data model is bespoke to each Oracle/feed and built by the Chronicle team, using only tier-one primary sources. Although a weighting methodology is applied to the data sources, the exact weighting remains unknown for security reasons. Nevertheless, the clear visualization of each validator’s reported values and the aggregation methodology on the Dashboard allows for independent verification of the aggregated data.
Data Publishing & Archiving
Chronicle’s Dashboard publishes data from all validators that form the basis for Oracle updates. These messages can be viewed in perpetuity on the dashboard in addition to the final price reports, which can also be viewed on-chain using block explorers or other methods. Chronicle also maintains an archive off-chain in their own ‘Origin’ database, available to whitelisted validators. Every signed price message reported by each validator is stored off-chain in the Archiver, regardless of whether it is pushed on-chain, with historical price messages from 2019 to the present day. These historical messages can be permissionlessly accessed and cryptographically verified via the Chronicle dashboard.

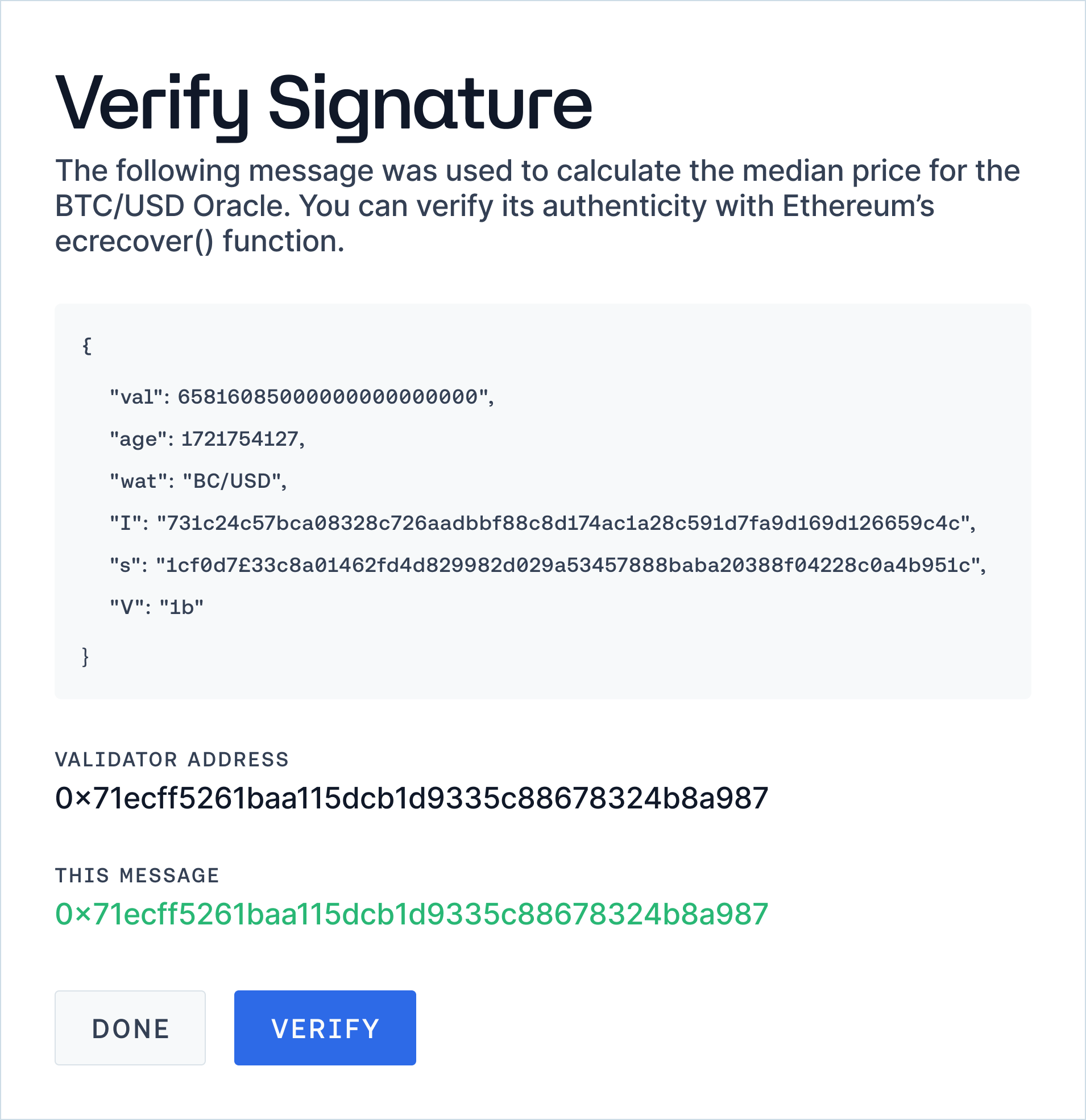
The authenticity of each price message can be challenged using Ethereum’s ecrecover function via the ‘Verify’ feature. This feature attempts to match the public address of the selected validator with the one produced by the signature of the message represented in the metadata, providing an accessible way for every user to verify the data reported by the Oracle network. This extensive and transparent data publishing and archiving process ensures that users can replicate and verify the historical and real-time data provided by Chronicle.
RedStone
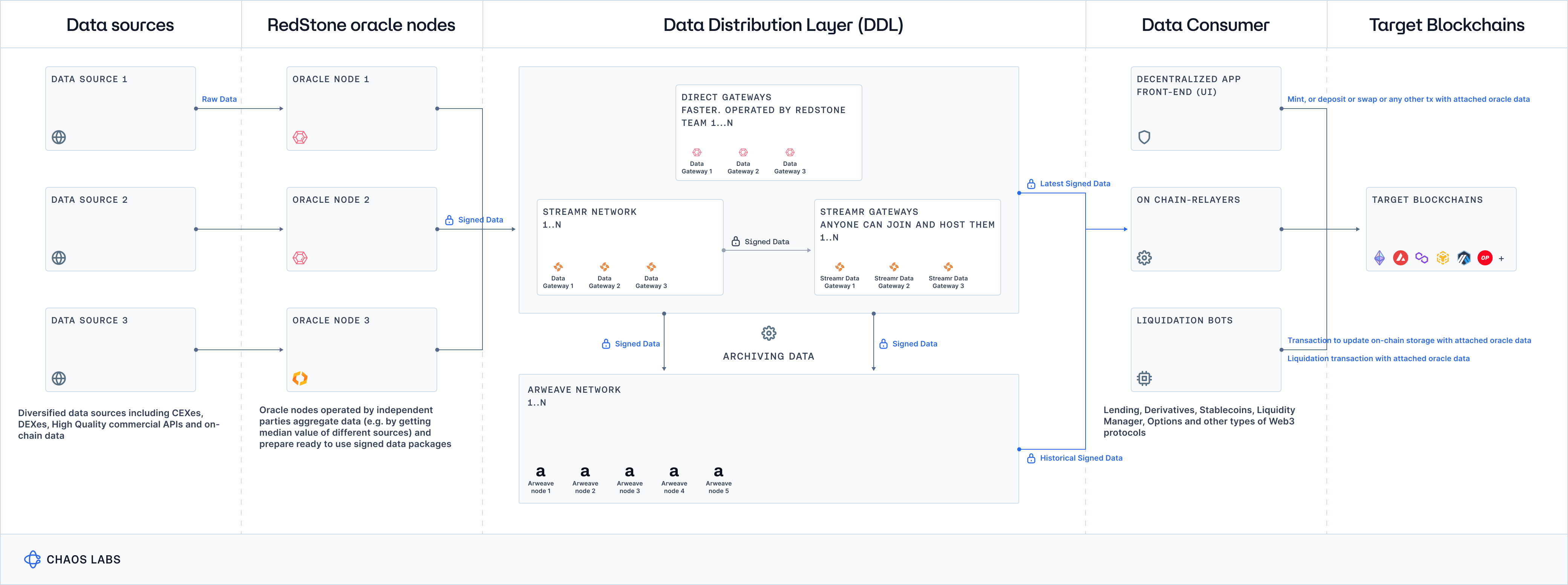
Data Sourcing
Each RedStone Oracle node prepares a manifesto that describes the data sources and pricing models it uses. The manifesto outlines the data sources and sanitization processes that each node adheres to, ensuring that the data is clean and reliable. However, this manifesto is not yet published on-chain and is not permissionlessly accessible, which limits data replicability. While this process provides clear insights into the data sources and sanitization methods, the lack of on-chain publication and permissionless access to the manifesto restricts third parties from fully verifying and replicating the data inputs.
Data Filtering & Aggregation
Following the initial data sourcing, a data filtering process is applied to remove clear outliers, such as asset prices that significantly differ from those on other exchanges or from values reported in the recent past. Data from multiple RedStone-operated nodes is then aggregated in a second phase, which occurs on-chain in the data feed smart contract. This smart contract calculates the median of medians among the Oracle nodes, a method that helps eliminate outliers and ensures robust price reporting. This transparent aggregation process supports partial data replicability by allowing third parties to independently verify the second-phase median calculation, but doesn’t allow full replicability as the first phase values and filtering methodologies remain unknown to third parties.
Data Publishing & Archiving
Historical price reports are archived on Arweave and are permissionlessly accessible. Interested parties can use Arweave’s public GraphQL endpoints to query and view historical prices. This allows developers familiar with Arweave to trace and verify historical price reports, maintaining a clear audit trail. The ability to access and independently verify both real-time and historical price reports provides a reference point for third parties to verify the accuracy of the reported prices.
Conclusion
Chapter 4 delved into the essential nature of data replicability within Oracle services, emphasizing its indispensable role in ensuring the reliability and trustworthiness of price data in DeFi ecosystems. The transparency of both data inputs and aggregation methodologies is especially important, allowing third parties to independently verify reported prices. By addressing the challenges of data source diversity and aggregation complexity through innovative solutions and multi-layered verification systems, Oracles can provide consistent and accurate price information. Ultimately, this strengthens user confidence and aligns with crucial DeFi principles: decentralization and transparency.
dYdX Chain: End of Season 6 Launch Incentive Analysis
Chaos Labs is pleased to provide a comprehensive review of the sixth trading season on the dYdX Chain. This analysis encompasses all facets of exchange performance, emphasizing the impact of the Launch Incentive Program.
dYdX Chain: End of Season 5 Launch Incentive Analysis
Chaos Labs presents a comprehensive review of the fifth trading season on the dYdX Chain. The analysis encompasses all facets of exchange performance, emphasizing the impact of the Launch Incentive Program.
Risk Less.
Know More.
Get updates on our research, product, and launch.